
D Learning Check Solutions
D.1 Chapter 2 Solutions
(LC2.1) Repeat the above installing steps, but for the dplyr, nycflights13, and knitr packages. This will install the earlier mentioned dplyr package, the nycflights13 package containing data on all domestic flights leaving a NYC airport in 2013, and the knitr package for writing reports in R.
(LC2.2) “Load” the dplyr, nycflights13, and knitr packages as well by repeating the above steps.
Solution: If the following code runs with no errors, you’ve succeeded!
(LC2.3) What does any ONE row in this flights dataset refer to?
- A. Data on an airline
- B. Data on a flight
- C. Data on an airport
- D. Data on multiple flights
Solution: This is data on a flight. Not a flight path! Example:
- a flight path would be United 1545 to Houston
- a flight would be United 1545 to Houston at a specific date/time. For example: 2013/1/1 at 5:15am.
(LC2.4) What are some examples in this dataset of categorical variables? What makes them different than quantitative variables?
Solution: Hint: Type ?flights in the console to see what all the variables mean!
- Categorical:
carrierthe companydestthe destinationflightthe flight number. Even though this is a number, its simply a label. Example United 1545 is not less than United 1714
- Quantitative:
distancethe distance in milestime_hourtime
(LC2.5) What properties of the observational unit do each of lat, lon, alt, tz, dst, and tzone describe for the airports data frame? Note that you may want to use ?airports to get more information.
Solution: lat long represent the airport geographic coordinates, alt is the altitude above sea level of the airport (Run airports %>% filter(faa == "DEN") to see the altitude of Denver International Airport), tz is the time zone difference with respect to GMT in London UK, dst is the daylight savings time zone, and tzone is the time zone label.
(LC2.6) Provide the names of variables in a data frame with at least three variables in which one of them is an identification variable and the other two are not. In other words, create your own tidy dataset that matches these conditions.
Solution:
- In the
weatherexample in LC3.8, the combination oforigin,year,month,day,hourare identification variables as they identify the observation in question. - Anything else pertains to observations:
temp,humid,wind_speed, etc.
D.2 Chapter 3 Solutions
(LC3.1) Take a look at both the flights and alaska_flights data frames by running View(flights) and View(alaska_flights) in the console. In what respect do these data frames differ? For example, think about the number of rows in each dataset.
Solution: flights contains all flight data, while alaska_flights contains only data from Alaskan carrier “AS”. We can see that flights has 336776 rows while alaska_flights has only 714
(LC3.2) What are some practical reasons why dep_delay and arr_delay have a positive relationship?
Solution: The later a plane departs, typically the later it will arrive.
(LC3.3) What variables in the weather data frame would you expect to have a negative correlation (i.e. a negative relationship) with dep_delay? Why? Remember that we are focusing on numerical variables here. Hint: Explore the weather dataset by using the View() function.
Solution: An example in the weather dataset is visibility, which measure visibility in miles. As visibility increases, we would expect departure delays to decrease.
(LC3.4) Why do you believe there is a cluster of points near (0, 0)? What does (0, 0) correspond to in terms of the Alaskan flights?
Solution: The point (0,0) means no delay in departure nor arrival. From the point of view of Alaska airlines, this means the flight was on time. It seems most flights are at least close to being on time.
(LC3.5) What are some other features of the plot that stand out to you?
Solution: Different people will answer this one differently. One answer is most flights depart and arrive less than an hour late.
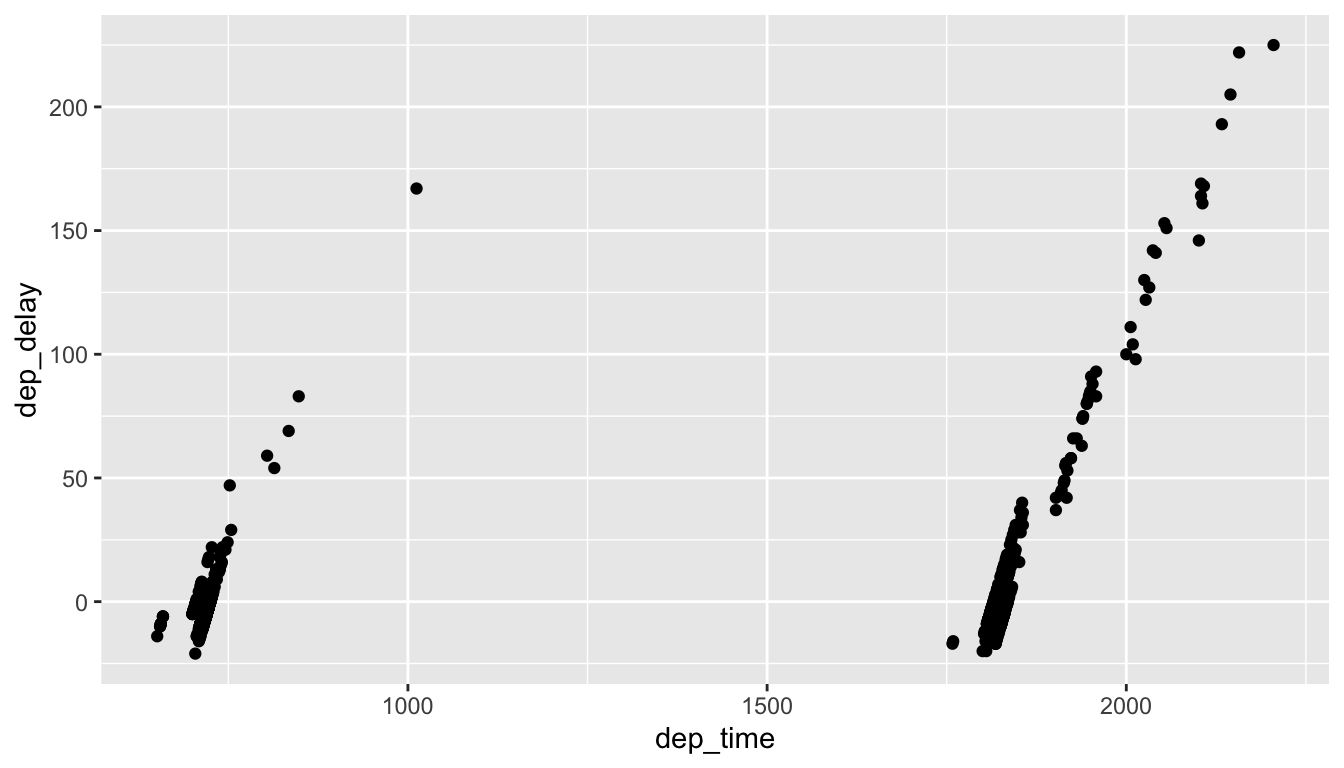
(LC3.6) Create a new scatterplot using different variables in the alaska_flights data frame by modifying the example above.
Solution: Many possibilities for this one, see the plot below. Is there a pattern in departure delay depending on when the flight is scheduled to depart? Interestingly, there seems to be only two blocks of time where flights depart.
(LC3.7) Why is setting the alpha argument value useful with scatterplots? What further information does it give you that a regular scatterplot cannot?
Solution: Why is setting the alpha argument value useful with scatterplots? What further information does it give you that a regular scatterplot cannot? It thins out the points so we address overplotting. But more importantly it hints at the (statistical) density and distribution of the points: where are the points concentrated, where do they occur.
(LC3.8) After viewing the Figure 2.4 above, give an approximate range of arrival delays and departure delays that occur the most frequently. How has that region changed compared to when you observed the same plot without the alpha = 0.2 set in Figure 2.2?
Solution: After viewing the Figure 2.4 above, give a range of arrival delays and departure delays that occur most frequently? How has that region changed compared to when you observed the same plot without the alpha = 0.2 set in Figure 2.2? The lower plot suggests that most Alaska flights from NYC depart between 12 minutes early and on time and arrive between 50 minutes early and on time.
(LC3.9) Take a look at both the weather and early_january_weather data frames by running View(weather) and View(early_january_weather) in the console. In what respect do these data frames differ?
Solution: Take a look at both the weather and early_january_weather data frames by running View(weather) and View(early_january_weather) in the console. In what respect do these data frames differ? The rows of early_january_weather are a subset of weather.
(LC3.10) View() the flights data frame again. Why does the time_hour variable uniquely identify the hour of the measurement whereas the hour variable does not?
Solution: View() the flights data frame again. Why does the time_hour variable correctly identify the hour of the measurement whereas the hour variable does not? Because to uniquely identify an hour, we need the year/month/day/hour sequence, whereas there are only 24 possible hour’s.
(LC3.11) Why should linegraphs be avoided when there is not a clear ordering of the horizontal axis?
Solution: Why should linegraphs be avoided when there is not a clear ordering of the horizontal axis? Because lines suggest connectedness and ordering.
(LC3.12) Why are linegraphs frequently used when time is the explanatory variable?
Solution: Why are linegraphs frequently used when time is the explanatory variable? Because time is sequential: subsequent observations are closely related to each other.
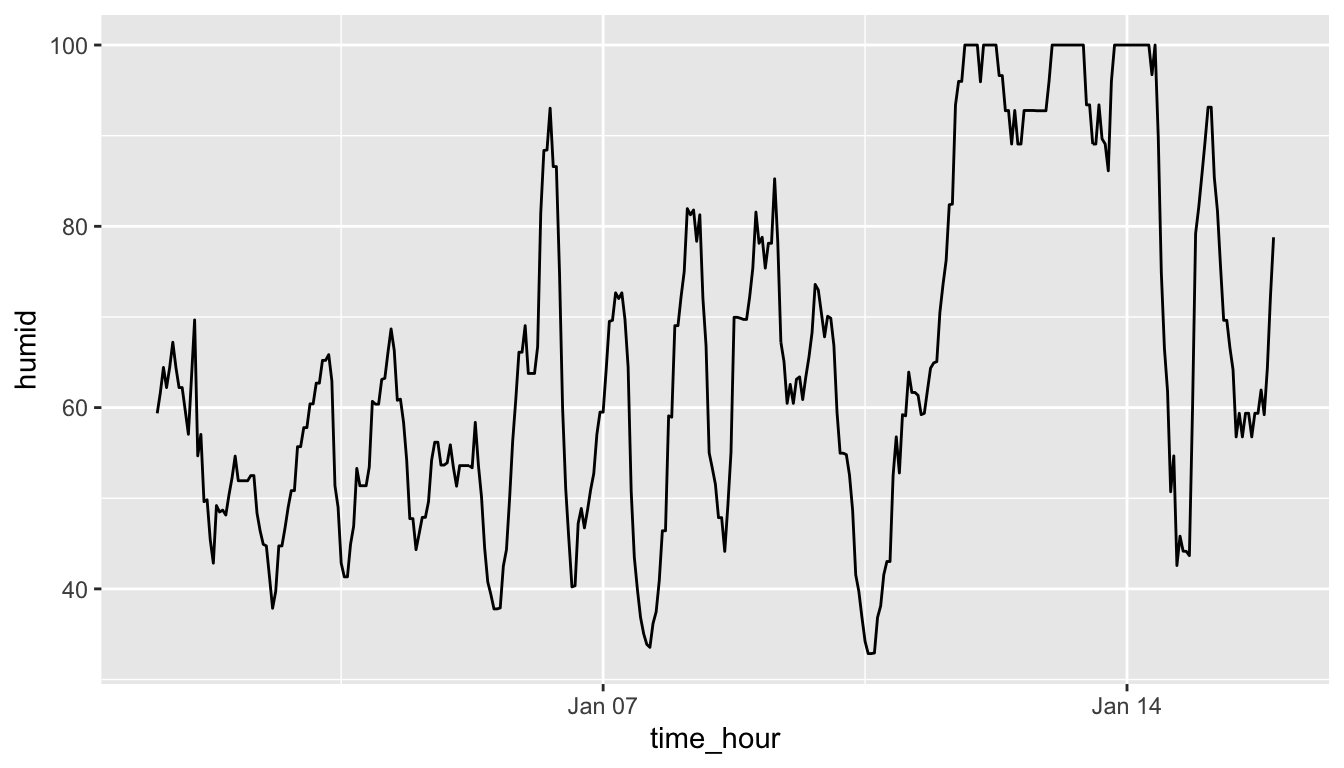
(LC3.13) Plot a time series of a variable other than temp for Newark Airport in the first 15 days of January 2013.
Solution: Plot a time series of a variable other than temp for Newark Airport in the first 15 days of January 2013. Humidity is a good one to look at, since this very closely related to the cycles of a day.
(LC3.14) What does changing the number of bins from 30 to 40 tell us about the distribution of temperatures?
Solution: The distribution doesn’t change much. But by refining the bin width, we see that the temperature data has a high degree of accuracy. What do I mean by accuracy? Looking at the temp variabile by View(weather), we see that the precision of each temperature recording is 2 decimal places.
(LC3.15) Would you classify the distribution of temperatures as symmetric or skewed?
Solution: It is rather symmetric, i.e. there are no long tails on only one side of the distribution
(LC3.16) What would you guess is the “center” value in this distribution? Why did you make that choice?
Solution: The center is around 55.26°F. By running the summary() command, we see that the mean and median are very similar. In fact, when the distribution is symmetric the mean equals the median.
(LC3.17) Is this data spread out greatly from the center or is it close? Why?
Solution: This can only be answered relatively speaking! Let’s pick things to be relative to Seattle, WA temperatures:
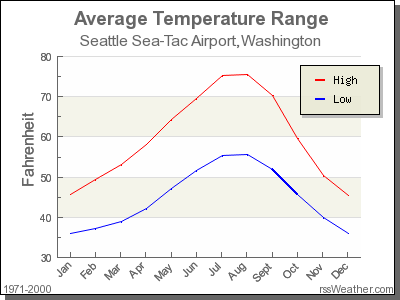
FIGURE D.1: Annual temperatures at SEATAC Airport.
While, it appears that Seattle weather has a similar center of 55°F, its temperatures are almost entirely between 35°F and 75°F for a range of about 40°F. Seattle temperatures are much less spread out than New York i.e. much more consistent over the year. New York on the other hand has much colder days in the winter and much hotter days in the summer. Expressed differently, the middle 50% of values, as delineated by the interquartile range is 30°F:
(LC3.18) What other things do you notice about the faceted plot above? How does a faceted plot help us see relationships between two variables?
Solution:
- Certain months have much more consistent weather (August in particular), while others have crazy variability like January and October, representing changes in the seasons.
- Because we see
temprecordings split bymonth, we are considering the relationship between these two variables. For example, for summer months, temperatures tend to be higher.
(LC3.19) What do the numbers 1-12 correspond to in the plot above? What about 25, 50, 75, 100?
Solution:
- They correspond to the month of the flight. While month is technically a number between 1-12, we’re viewing it as a categorical variable here. Specifically, this is an ordinal categorical variable since there is an ordering to the categories.
- 25, 50, 75, 100 are temperatures
(LC3.20) For which types of datasets would these types of faceted plots not work well in comparing relationships between variables? Give an example describing the nature of these variables and other important characteristics.
Solution:
- It would not work if we had a very large number of facets. For example, if we facetted by individual days rather than months, as we would have 365 facets to look at. When considering all days in 2013, it could be argued that we shouldn’t care about day-to-day fluctuation in weather so much, but rather month-to-month fluctuations, allowing us to focus on seasonal trends.
(LC3.21) Does the temp variable in the weather data-set have a lot of variability? Why do you say that?
Solution: Again, like in LC (LC3.17), this is a relative question. I would say yes, because in New York City, you have 4 clear seasons with different weather. Whereas in Seattle WA and Portland OR, you have two seasons: summer and rain!
(LC3.22) What does the dot at the bottom of the plot for May correspond to? Explain what might have occurred in May to produce this point.
Solution: It appears to be an outlier. Let’s revisit the use of the filter command to hone in on it. We want all data points where the month is 5 and temp<25
# A tibble: 1 x 16
origin year month day hour temp dewp humid wind_dir wind_speed wind_gust
<chr> <int> <int> <int> <int> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 JFK 2013 5 8 22 13.1 12.02 95.34 80 8.05546 NA
# … with 5 more variables: precip <dbl>, pressure <dbl>, visib <dbl>,
# time_hour <dttm>, temp_in_C <dbl>There appears to be only one hour and only at JFK that recorded 13.1 F (-10.5 C) in the month of May. This is probably a data entry mistake! Why wasn’t the weather at least similar at EWR (Newark) and LGA (La Guardia)?
(LC3.23) Which months have the highest variability in temperature? What reasons do you think this is?
Solution: We are now interested in the spread of the data. One measure some of you may have seen previously is the standard deviation. But in this plot we can read off the Interquartile Range (IQR):
- The distance from the 1st to the 3rd quartiles i.e. the length of the boxes
- You can also think of this as the spread of the middle 50% of the data
Just from eyeballing it, it seems
- November has the biggest IQR, i.e. the widest box, so has the most variation in temperature
- August has the smallest IQR, i.e. the narrowest box, so is the most consistent temperature-wise
Here’s how we compute the exact IQR values for each month (we’ll see this more in depth Chapter 3 of the text):
groupthe observations bymonththen- for each
group, i.e.month,summarizeit by applying the summary statistic functionIQR(), while making sure to skip over missing data viana.rm=TRUEthen arrangethe table indescending order ofIQR
| month | IQR |
|---|---|
| 11 | 16.02 |
| 12 | 14.04 |
| 1 | 13.77 |
| 9 | 12.06 |
| 4 | 12.06 |
| 5 | 11.88 |
| 6 | 10.98 |
| 10 | 10.98 |
| 2 | 10.08 |
| 7 | 9.18 |
| 3 | 9.00 |
| 8 | 7.02 |
(LC3.24) We looked at the distribution of the numerical variable temp split by the numerical variable month that we converted to a categorical variable using the factor() function. Why would a boxplot of temp split by the numerical variable pressure similarly converted to a categorical variable using the factor() not be informative?
Solution: Because there are 12 unique values of month yielding only 12 boxes in our boxplot. There are many more unique values of pressure (469 unique values in fact), because values are to the first decimal place. This would lead to 469 boxes, which is too many for people to digest.
(LC3.25) Boxplots provide a simple way to identify outliers. Why may outliers be easier to identify when looking at a boxplot instead of a faceted histogram?
Solution: In a histogram, the bin corresponding to where an outlier lies may not by high enough for us to see. In a boxplot, they are explicitly labelled separately.
(LC3.26) Why are histograms inappropriate for visualizing categorical variables?
Solution: Histograms are for numerical variables i.e. the horizontal part of each histogram bar represents an interval, whereas for a categorical variable each bar represents only one level of the categorical variable.
(LC3.27) What is the difference between histograms and barplots?
Solution: See above.
(LC3.28) How many Envoy Air flights departed NYC in 2013?
Solution: Envoy Air is carrier code MQ and thus 26397 flights departed NYC in 2013.
(LC3.29) What was the seventh highest airline in terms of departed flights from NYC in 2013? How could we better present the table to get this answer quickly?
Solution: The answer is US, AKA U.S. Airways, with 20536 flights. However, picking out the seventh highest airline when the rows are sorted alphabetically by carrier code is difficult. This would be easier to do if the rows were sorted by number. We’ll learn how to do this in Chapter 3 on data wrangling.
(LC3.30) Why should pie charts be avoided and replaced by barplots?
Solution: In our opinion, comparisons using horizontal lines are easier than comparing angles and areas of circles.
(LC3.31) What is your opinion as to why pie charts continue to be used?
Solution: Legacy?
(LC3.32) What kinds of questions are not easily answered by looking at the above figure?
Solution: Because the red, green, and blue bars don’t all start at 0 (only red does), it makes comparing counts hard.
(LC3.33) What can you say, if anything, about the relationship between airline and airport in NYC in 2013 in regards to the number of departing flights?
Solution: The different airlines prefer different airports. For example, United is mostly a Newark carrier and JetBlue is a JFK carrier. If airlines didn’t prefer airports, each color would be roughly one third of each bar.}
(LC3.34) Why might the side-by-side (AKA dodged) barplot be preferable to a stacked barplot in this case?
Solution: We can easily compare the different aiports for a given carrier using a single comparison line i.e. things are lined up
(LC3.35) What are the disadvantages of using a side-by-side (AKA dodged) barplot, in general?
Solution: It is hard to get totals for each airline.
(LC3.36) Why is the faceted barplot preferred to the side-by-side and stacked barplots in this case?
Solution: Not that different than using side-by-side; depends on how you want to organize your presentation.
(LC3.37) What information about the different carriers at different airports is more easily seen in the faceted barplot?
Solution: Now we can also compare the different carriers within a particular airport easily too. For example, we can read off who the top carrier for each airport is easily using a single horizontal line.
D.3 Chapter 4 Solutions
(LC4.1) What’s another way using the “not” operator ! to filter only the rows that are not going to Burlington, VT nor Seattle, WA in the flights data frame? Test this out using the code above.
Solution:
# Original in book
not_BTV_SEA <- flights %>%
filter(!(dest == "BTV" | dest == "SEA"))
# Alternative way
not_BTV_SEA <- flights %>%
filter(!dest == "BTV" & !dest == "SEA")
# Yet another way
not_BTV_SEA <- flights %>%
filter(dest != "BTV" & dest != "SEA")(LC4.2) Say a doctor is studying the effect of smoking on lung cancer for a large number of patients who have records measured at five year intervals. She notices that a large number of patients have missing data points because the patient has died, so she chooses to ignore these patients in her analysis. What is wrong with this doctor’s approach?
Solution: The missing patients may have died of lung cancer! So to ignore them might seriously bias your results! It is very important to think of what the consequences on your analysis are of ignoring missing data! Ask yourself:
- There is a systematic reasons why certain values are missing? If so, you might be biasing your results!
- If there isn’t, then it might be ok to “sweep missing values under the rug.”
(LC4.3) Modify the above summarize function to create summary_temp to also use the n() summary function: summarize(count = n()). What does the returned value correspond to?
Solution: It corresponds to a count of the number of observations/rows:
# A tibble: 1 x 1
count
<int>
1 26115(LC4.4) Why doesn’t the following code work? Run the code line by line instead of all at once, and then look at the data. In other words, run summary_temp <- weather %>% summarize(mean = mean(temp, na.rm = TRUE)) first.
summary_temp <- weather %>%
summarize(mean = mean(temp, na.rm = TRUE)) %>%
summarize(std_dev = sd(temp, na.rm = TRUE))Solution: Consider the output of only running the first two lines:
# A tibble: 1 x 1
mean
<dbl>
1 55.2604Because after the first summarize(), the variable temp disappears as it has been collapsed to the value mean. So when we try to run the second summarize(), it can’t find the variable temp to compute the standard deviation of.
(LC4.5) Recall from Chapter 2 when we looked at plots of temperatures by months in NYC. What does the standard deviation column in the summary_monthly_temp data frame tell us about temperatures in New York City throughout the year?
Solution:
The standard deviation is a quantification of spread and variability. We see that the period in November, December, and January has the most variation in weather, so you can expect very different temperatures on different days.
(LC4.6) What code would be required to get the mean and standard deviation temperature for each day in 2013 for NYC?
Solution:
Note: group_by(day) is not enough, because day is a value between 1-31. We need to group_by(year, month, day)
library(dplyr)
library(nycflights13)
summary_temp_by_month <- weather %>%
group_by(month) %>%
summarize(
mean = mean(temp, na.rm = TRUE),
std_dev = sd(temp, na.rm = TRUE)
)(LC4.7) Recreate by_monthly_origin, but instead of grouping via group_by(origin, month), group variables in a different order group_by(month, origin). What differs in the resulting dataset?
Solution:
In by_monthly_origin the month column is now first and the rows are sorted by month instead of origin. If you compare the values of count in by_origin_monthly and by_monthly_origin using the View() function, you’ll see that the values are actually the same, just presented in a different order.
(LC4.8) How could we identify how many flights left each of the three airports for each carrier?
Solution: We could summarize the count from each airport using the n() function, which counts rows.
All remarkably similar! Note: the n() function counts rows, whereas the sum(VARIABLE_NAME) funciton sums all values of a certain numerical variable VARIABLE_NAME.
(LC4.9) How does the filter operation differ from a group_by followed by a summarize?
Solution:
filterpicks out rows from the original dataset without modifying them, whereasgroup_by %>% summarizecomputes summaries of numerical variables, and hence reports new values.
(LC4.10) What do positive values of the gain variable in flights correspond to? What about negative values? And what about a zero value?
Solution:
- Say a flight departed 20 minutes late, i.e.
dep_delay = 20 - Then arrived 10 minutes late, i.e.
arr_delay = 10. - Then
gain = dep_delay - arr_delay = 20 - 10 = 10is positive, so it “made up/gained time in the air.” - 0 means the departure and arrival time were the same, so no time was made up in the air. We see in most cases that the
gainis near 0 minutes. - I never understood this. If the pilot says “we’re going make up time in the air” because of delay by flying faster, why don’t you always just fly faster to begin with?
(LC4.11) Could we create the dep_delay and arr_delay columns by simply subtracting dep_time from sched_dep_time and similarly for arrivals? Try the code out and explain any differences between the result and what actually appears in flights.
Solution: No because you can’t do direct arithmetic on times. The difference in time between 12:03 and 11:59 is 4 minutes, but 1203-1159 = 44
(LC4.12) What can we say about the distribution of gain? Describe it in a few sentences using the plot and the gain_summary data frame values.
Solution: Most of the time the gain is a little under zero, most of the time the gain is between -50 and 50 minutes. There are some extreme cases however!
(LC4.13) Looking at Figure 3.7, when joining flights and weather (or, in other words, matching the hourly weather values with each flight), why do we need to join by all of year, month, day, hour, and origin, and not just hour?
Solution: Because hour is simply a value between 0 and 23; to identify a specific hour, we need to know which year, month, day and at which airport.
(LC4.14) What surprises you about the top 10 destinations from NYC in 2013?
Solution: This question is subjective! What surprises me is the high number of flights to Boston. Wouldn’t it be easier and quicker to take the train?
(LC4.15) What are some advantages of data in normal forms? What are some disadvantages?
Solution: When datasets are in normal form, we can easily _join them with other datasets! For example, we can join the flights data with the planes data.
(LC4.16) What are some ways to select all three of the dest, air_time, and distance variables from flights? Give the code showing how to do this in at least three different ways.
Solution:
(LC4.17) How could one use starts_with, ends_with, and contains to select columns from the flights data frame? Provide three different examples in total: one for starts_with, one for ends_with, and one for contains.
Solution:
(LC4.18) Why might we want to use the select() function on a data frame?
Solution: To narrow down the data frame, to make it easier to look at. Using View() for example.
(LC4.19) Create a new data frame that shows the top 5 airports with the largest arrival delays from NYC in 2013.
Solution:
(LC4.20) Using the datasets included in the nycflights13 package, compute the available seat miles for each airline sorted in descending order. After completing all the necessary data wrangling steps, the resulting data frame should have 16 rows (one for each airline) and 2 columns (airline name and available seat miles). Here are some hints:
- Crucial: Unless you are very confident in what you are doing, it is worthwhile to not starting coding right away, but rather first sketch out on paper all the necessary data wrangling steps not using exact code, but rather high-level pseudocode that is informal yet detailed enough to articulate what you are doing. This way you won’t confuse what you are trying to do (the algorithm) with how you are going to do it (writing
dplyrcode). - Take a close look at all the datasets using the
View()function:flights,weather,planes,airports, andairlinesto identify which variables are necessary to compute available seat miles. - Figure 3.7 above showing how the various datasets can be joined will also be useful.
- Consider the data wrangling verbs in Table 3.2 as your toolbox!
Solution: Here are some examples of student-written pseudocode. Based on our own pseudocode, let’s first display the entire solution.
Let’s now break this down step-by-step. To compute the available seat miles for a given flight, we need the distance variable from the flights data frame and the seats variable from the planes data frame, necessitating a join by the key variable tailnum as illustrated in Figure 3.7. To keep the resulting data frame easy to view, we’ll select() only these two variables and carrier:
Now for each flight we can compute the available seat miles ASM by multiplying the number of seats by the distance via a mutate():
Next we want to sum the ASM for each carrier. We achieve this by first grouping by carrier and then summarizing using the sum() function:
However, because for certain carriers certain flights have missing NA values, the resulting table also returns NA’s. We can eliminate these by adding a na.rm = TRUE argument to sum(), telling R that we want to remove the NA’s in the sum. We saw this in Section 3.3:
Finally, we arrange() the data in desc()ending order of ASM.
While the above data frame is correct, the IATA carrier code is not always useful. For example, what carrier is WN? We can address this by joining with the airlines dataset using carrier is the key variable. While this step is not absolutely required, it goes a long way to making the table easier to make sense of. It is important to be empathetic with the ultimate consumers of your presented data!
D.4 Chapter 5 Solutions
(LC5.1) What are common characteristics of “tidy” datasets?
Solution: Rows correspond to observations, while columns correspond to variables.
(LC5.2) What makes “tidy” datasets useful for organizing data?
Solution: Tidy datasets are an organized way of viewing data. This format is required for the ggplot2 and dplyr packages for data visualization and wrangling.
(LC5.3) Take a look the airline_safety data frame included in the fivethirtyeight data. Run the following:
After reading the help file by running ?airline_safety, we see that airline_safety is a data frame containing information on different airlines companies’ safety records. This data was originally reported on the data journalism website FiveThirtyEight.com in Nate Silver’s article “Should Travelers Avoid Flying Airlines That Have Had Crashes in the Past?”. Let’s ignore the incl_reg_subsidiaries and avail_seat_km_per_week variables for simplicity:
airline_safety_smaller <- airline_safety %>%
select(-c(incl_reg_subsidiaries, avail_seat_km_per_week))
airline_safety_smaller# A tibble: 56 x 7
airline incidents_85_99 fatal_accidents… fatalities_85_99 incidents_00_14
<chr> <int> <int> <int> <int>
1 Aer Li… 2 0 0 0
2 Aerofl… 76 14 128 6
3 Aeroli… 6 0 0 1
4 Aerome… 3 1 64 5
5 Air Ca… 2 0 0 2
6 Air Fr… 14 4 79 6
7 Air In… 2 1 329 4
8 Air Ne… 3 0 0 5
9 Alaska… 5 0 0 5
10 Alital… 7 2 50 4
# … with 46 more rows, and 2 more variables: fatal_accidents_00_14 <int>,
# fatalities_00_14 <int>This data frame is not in “tidy” format. How would you convert this data frame to be in “tidy” format, in particular so that it has a variable incident_type_years indicating the indicent type/year and a variable count of the counts?
Solution: Using the gather() function from the tidyr package:
airline_safety_smaller_tidy <- airline_safety_smaller %>%
gather(key = incident_type_years, value = count, -airline)
airline_safety_smaller_tidy# A tibble: 336 x 3
airline incident_type_years count
<chr> <chr> <int>
1 Aer Lingus incidents_85_99 2
2 Aeroflot incidents_85_99 76
3 Aerolineas Argentinas incidents_85_99 6
4 Aeromexico incidents_85_99 3
5 Air Canada incidents_85_99 2
6 Air France incidents_85_99 14
7 Air India incidents_85_99 2
8 Air New Zealand incidents_85_99 3
9 Alaska Airlines incidents_85_99 5
10 Alitalia incidents_85_99 7
# … with 326 more rowsIf you look at the resulting airline_safety_smaller_tidy data frame in the spreadsheet viewer, you’ll see that the variable incident_type_years has 6 possible values: "incidents_85_99", "fatal_accidents_85_99", "fatalities_85_99", "incidents_00_14", "fatal_accidents_00_14", "fatalities_00_14" corresponding to the 6 columns of airline_safety_smaller we tidied.
(LC5.4) Convert the dem_score data frame into
a tidy data frame and assign the name of dem_score_tidy to the resulting long-formatted data frame.
Solution: Running the following in the console:
Let’s now compare the dem_score and dem_score_tidy. dem_score has democracy score information for each year in columns, whereas in dem_score_tidy there are explicit variables year and democracy_score. While both representations of the data contain the same information, we can only use ggplot() to create plots using the dem_score_tidy data frame.
(LC5.5) Read in the life expectancy data stored at https://moderndive.com/data/le_mess.csv and convert it to a tidy data frame.
Solution: The code is similar
We observe the same construct structure with respect to year in life_expectancy vs life_expectancy_tidy as we did in dem_score vs dem_score_tidy:
D.5 Chapter 6 Solutions
To come!