
Chapter 10 Hypothesis Testing
In preparation for our first print edition to be published by CRC Press in Fall 2019, we’re remodeling this chapter a bit. Don’t expect major changes in content, but rather only minor changes in presentation. Our remodeling will be complete and available online at ModernDive.com by early Summer 2019!
We saw some of the main concepts of hypothesis testing introduced in Chapters 8 and 9. We will expand further on these ideas here and also provide a framework for understanding hypothesis tests in general. Instead of presenting you with lots of different formulas and scenarios, we hope to build a way to think about all hypothesis tests. You can then adapt to different scenarios as needed down the road when you encounter different statistical situations.
The same can be said for confidence intervals. There was one general framework that applies to all confidence intervals and we elaborated on this using the infer package pipeline in Chapter 9. The specifics may change slightly for each variation, but the important idea is to understand the general framework so that you can apply it to more specific problems. We believe that this approach is much better in the long-term than teaching you specific tests and confidence intervals rigorously. You can find fully-worked out examples for five common hypothesis tests and their corresponding confidence intervals in Appendix B.
We recommend that you carefully review these examples as they also cover how the general frameworks apply to traditional normal-based methodologies like the \(t\)-test and normal-theory confidence intervals. You’ll see there that these methods are just approximations for the general computational frameworks, but require conditions to be met for their results to be valid. The general frameworks using randomization, simulation, and bootstrapping do not hold the same sorts of restrictions and further advance computational thinking, which is one big reason for their emphasis throughout this textbook.
Needed packages
Let’s load all the packages needed for this chapter (this assumes you’ve already installed them). If needed, read Section 2.3 for information on how to install and load R packages.
library(dplyr)
library(ggplot2)
library(infer)
library(nycflights13)
library(ggplot2movies)
library(broom)We saw some of the main concepts of hypothesis testing introduced in Chapters 8 and 9. We will expand further on these ideas here and also provide a framework for understanding hypothesis tests in general. Instead of presenting you with lots of different formulas and scenarios, we hope to build a way to think about all hypothesis tests. You can then adapt to different scenarios as needed down the road when you encounter different statistical situations.
The same can be said for confidence intervals. There was one general framework that applies to all confidence intervals and we elaborated on this using the infer package pipeline in Chapter 9. The specifics may change slightly for each variation, but the important idea is to understand the general framework so that you can apply it to more specific problems. We believe that this approach is much better in the long-term than teaching you specific tests and confidence intervals rigorously. You can find fully-worked out examples for five common hypothesis tests and their corresponding confidence intervals in Appendix B.
We recommend that you carefully review these examples as they also cover how the general frameworks apply to traditional normal-based methodologies like the \(t\)-test and normal-theory confidence intervals. You’ll see there that these methods are just approximations for the general computational frameworks, but require conditions to be met for their results to be valid. The general frameworks using randomization, simulation, and bootstrapping do not hold the same sorts of restrictions and further advance computational thinking, which is one big reason for their emphasis throughout this textbook.
Needed packages
Let’s load all the packages needed for this chapter (this assumes you’ve already installed them). If needed, read Section 2.3 for information on how to install and load R packages.
library(dplyr)
library(ggplot2)
library(infer)
library(nycflights13)
library(ggplot2movies)
library(broom)10.1 When inference is not needed
Before we delve into hypothesis testing, it’s good to remember that there are cases where you need not perform a rigorous statistical inference. An important and time-saving skill is to ALWAYS do exploratory data analysis using dplyr and ggplot2 before thinking about running a hypothesis test. Let’s look at such an example selecting a sample of flights traveling to Boston and to San Francisco from New York City in the flights data frame in the nycflights13 package. (We will remove flights with missing data first using na.omit and then sample 100 flights going to each of the two airports.)
bos_sfo <- flights %>%
na.omit() %>%
filter(dest %in% c("BOS", "SFO")) %>%
group_by(dest) %>%
sample_n(100)Suppose we were interested in seeing if the air_time to SFO in San Francisco was statistically greater than the air_time to BOS in Boston. As suggested, let’s begin with some exploratory data analysis to get a sense for how the two variables of air_time and dest relate for these two destination airports:
bos_sfo_summary <- bos_sfo %>% group_by(dest) %>%
summarize(mean_time = mean(air_time),
sd_time = sd(air_time))
bos_sfo_summary# A tibble: 2 x 3
dest mean_time sd_time
<chr> <dbl> <dbl>
1 BOS 39.0 4.51
2 SFO 349. 18.7 Looking at these results, we can clearly see that SFO air_time is much larger than BOS air_time. The standard deviation is also extremely informative here.
Learning check
(LC10.1) Could we make the same type of immediate conclusion that SFO had a statistically greater air_time if, say, its corresponding standard deviation was 200 minutes? What about 100 minutes? Explain.
To further understand just how different the air_time variable is for BOS and SFO, let’s look at a boxplot:
ggplot(data = bos_sfo, mapping = aes(x = dest, y = air_time)) +
geom_boxplot()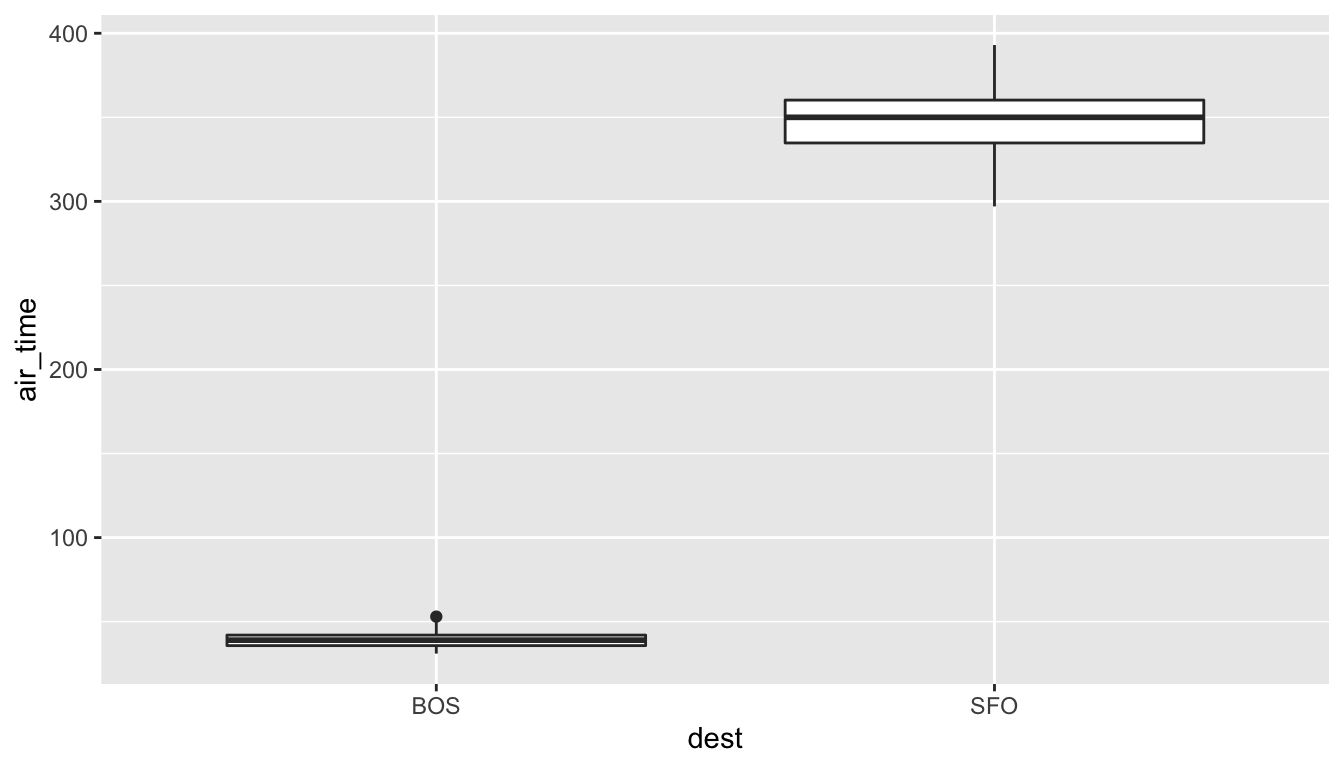
Since there is no overlap at all, we can conclude that the air_time for San Francisco flights is statistically greater (at any level of significance) than the air_time for Boston flights. This is a clear example of not needing to do anything more than some simple exploratory data analysis with descriptive statistics and data visualization to get an appropriate inferential conclusion. This is one reason why you should ALWAYS investigate the sample data first using dplyr and ggplot2 via exploratory data analysis.
As you get more and more practice with hypothesis testing, you’ll be better able to determine in many cases whether or not the results will be statistically significant. There are circumstances where it is difficult to tell, but you should always try to make a guess FIRST about significance after you have completed your data exploration and before you actually begin the inferential techniques.
10.2 Basics of hypothesis testing
In a hypothesis test, we will use data from a sample to help us decide between two competing hypotheses about a population. We make these hypotheses more concrete by specifying them in terms of at least one population parameter of interest. We refer to the competing claims about the population as the null hypothesis, denoted by \(H_0\), and the alternative (or research) hypothesis, denoted by \(H_a\). The roles of these two hypotheses are NOT interchangeable.
- The claim for which we seek significant evidence is assigned to the alternative hypothesis. The alternative is usually what the experimenter or researcher wants to establish or find evidence for.
- Usually, the null hypothesis is a claim that there really is “no effect” or “no difference.” In many cases, the null hypothesis represents the status quo or that nothing interesting is happening.
- We assess the strength of evidence by assuming the null hypothesis is true and determining how unlikely it would be to see sample results/statistics as extreme (or more extreme) as those in the original sample.
Hypothesis testing brings about many weird and incorrect notions in the scientific community and society at large. One reason for this is that statistics has traditionally been thought of as this magic box of algorithms and procedures to get to results and this has been readily apparent if you do a Google search of “flowchart statistics hypothesis tests.” There are so many different complex ways to determine which test is appropriate.
You’ll see that we don’t need to rely on these complicated series of assumptions and procedures to conduct a hypothesis test any longer. These methods were introduced in a time when computers weren’t powerful. Your cellphone (in 2016) has more power than the computers that sent NASA astronauts to the moon after all. We’ll see that ALL hypothesis tests can be broken down into the following framework given by Allen Downey here:
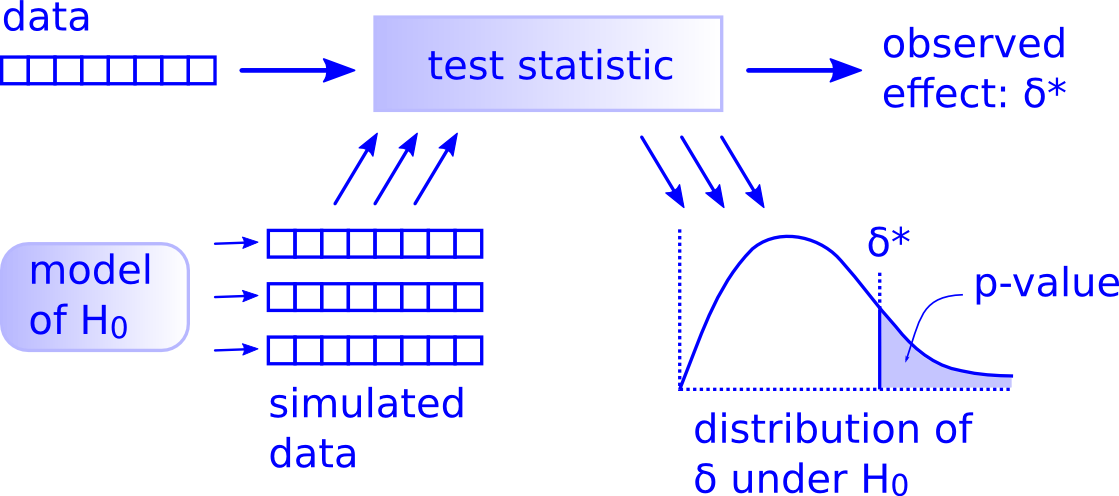
FIGURE 10.1: Hypothesis Testing Framework
Before we hop into this framework, we will provide another way to think about hypothesis testing that may be useful.
10.3 Criminal trial analogy
We can think of hypothesis testing in the same context as a criminal trial in the United States. A criminal trial in the United States is a familiar situation in which a choice between two contradictory claims must be made.
The accuser of the crime must be judged either guilty or not guilty.
Under the U.S. system of justice, the individual on trial is initially presumed not guilty.
Only STRONG EVIDENCE to the contrary causes the not guilty claim to be rejected in favor of a guilty verdict.
The phrase “beyond a reasonable doubt” is often used to set the cutoff value for when enough evidence has been given to convict.
Theoretically, we should never say “The person is innocent.” but instead “There is not sufficient evidence to show that the person is guilty.”
Now let’s compare that to how we look at a hypothesis test.
The decision about the population parameter(s) must be judged to follow one of two hypotheses.
We initially assume that \(H_0\) is true.
The null hypothesis \(H_0\) will be rejected (in favor of \(H_a\)) only if the sample evidence strongly suggests that \(H_0\) is false. If the sample does not provide such evidence, \(H_0\) will not be rejected.
The analogy to “beyond a reasonable doubt” in hypothesis testing is what is known as the significance level. This will be set before conducting the hypothesis test and is denoted as \(\alpha\). Common values for \(\alpha\) are 0.1, 0.01, and 0.05.
10.3.1 Two possible conclusions
Therefore, we have two possible conclusions with hypothesis testing:
- Reject \(H_0\)
- Fail to reject \(H_0\)
Gut instinct says that “Fail to reject \(H_0\)” should say “Accept \(H_0\)” but this technically is not correct. Accepting \(H_0\) is the same as saying that a person is innocent. We cannot show that a person is innocent; we can only say that there was not enough substantial evidence to find the person guilty.
When you run a hypothesis test, you are the jury of the trial. You decide whether there is enough evidence to convince yourself that \(H_a\) is true (“the person is guilty”) or that there was not enough evidence to convince yourself \(H_a\) is true (“the person is not guilty”). You must convince yourself (using statistical arguments) which hypothesis is the correct one given the sample information.
Important note: Therefore, DO NOT WRITE “Accept \(H_0\)” any time you conduct a hypothesis test. Instead write “Fail to reject \(H_0\).”
10.4 Types of errors in hypothesis testing
Unfortunately, just as a jury or a judge can make an incorrect decision in regards to a criminal trial by reaching the wrong verdict, there is some chance we will reach the wrong conclusion via a hypothesis test about a population parameter. As with criminal trials, this comes from the fact that we don’t have complete information, but rather a sample from which to try to infer about a population.
The possible erroneous conclusions in a criminal trial are
- an innocent person is convicted (found guilty) or
- a guilty person is set free (found not guilty).
The possible errors in a hypothesis test are
- rejecting \(H_0\) when in fact \(H_0\) is true (Type I Error) or
- failing to reject \(H_0\) when in fact \(H_0\) is false (Type II Error).
The risk of error is the price researchers pay for basing an inference about a population on a sample. With any reasonable sample-based procedure, there is some chance that a Type I error will be made and some chance that a Type II error will occur.
To help understand the concepts of Type I error and Type II error, observe the following table:
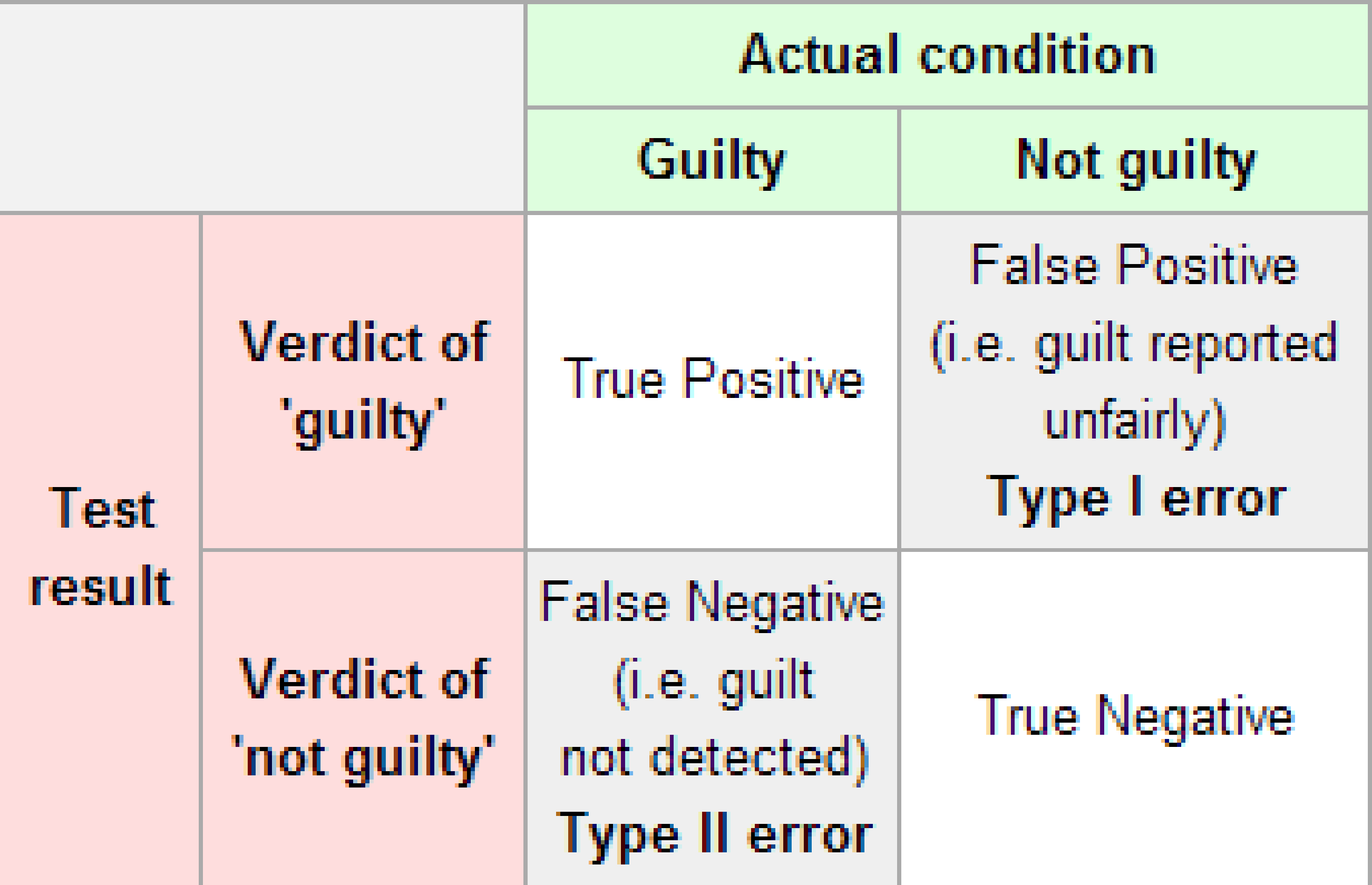
FIGURE 10.2: Type I and Type II errors
If we are using sample data to make inferences about a parameter, we run the risk of making a mistake. Obviously, we want to minimize our chance of error; we want a small probability of drawing an incorrect conclusion.
- The probability of a Type I Error occurring is denoted by \(\alpha\) and is called the significance level of a hypothesis test
- The probability of a Type II Error is denoted by \(\beta\).
Formally, we can define \(\alpha\) and \(\beta\) in regards to the table above, but for hypothesis tests instead of a criminal trial.
- \(\alpha\) corresponds to the probability of rejecting \(H_0\) when, in fact, \(H_0\) is true.
- \(\beta\) corresponds to the probability of failing to reject \(H_0\) when, in fact, \(H_0\) is false.
Ideally, we want \(\alpha = 0\) and \(\beta = 0\), meaning that the chance of making an error does not exist. When we have to use incomplete information (sample data), it is not possible to have both \(\alpha = 0\) and \(\beta = 0\). We will always have the possibility of at least one error existing when we use sample data.
Usually, what is done is that \(\alpha\) is set before the hypothesis test is conducted and then the evidence is judged against that significance level. Common values for \(\alpha\) are 0.05, 0.01, and 0.10. If \(\alpha = 0.05\), we are using a testing procedure that, used over and over with different samples, rejects a TRUE null hypothesis five percent of the time.
So if we can set \(\alpha\) to be whatever we want, why choose 0.05 instead of 0.01 or even better 0.0000000000000001? Well, a small \(\alpha\) means the test procedure requires the evidence against \(H_0\) to be very strong before we can reject \(H_0\). This means we will almost never reject \(H_0\) if \(\alpha\) is very small. If we almost never reject \(H_0\), the probability of a Type II Error – failing to reject \(H_0\) when we should – will increase! Thus, as \(\alpha\) decreases, \(\beta\) increases and as \(\alpha\) increases, \(\beta\) decreases. We, therefore, need to strike a balance in \(\alpha\) and \(\beta\) and the common values for \(\alpha\) of 0.05, 0.01, and 0.10 usually lead to a nice balance.
Learning check
(LC10.2) Reproduce the table above about errors, but for a hypothesis test, instead of the one provided for a criminal trial.
10.4.1 Logic of hypothesis testing
- Take a random sample (or samples) from a population (or multiple populations)
- If the sample data are consistent with the null hypothesis, do not reject the null hypothesis.
- If the sample data are inconsistent with the null hypothesis (in the direction of the alternative hypothesis), reject the null hypothesis and conclude that there is evidence the alternative hypothesis is true (based on the particular sample collected).
10.5 Statistical significance
The idea that sample results are more extreme than we would reasonably expect to see by random chance if the null hypothesis were true is the fundamental idea behind statistical hypothesis tests. If data at least as extreme would be very unlikely if the null hypothesis were true, we say the data are statistically significant. Statistically significant data provide convincing evidence against the null hypothesis in favor of the alternative, and allow us to generalize our sample results to the claim about the population.
Learning check
(LC10.3) What is wrong about saying “The defendant is innocent.” based on the US system of criminal trials?
(LC10.4) What is the purpose of hypothesis testing?
(LC10.5) What are some flaws with hypothesis testing? How could we alleviate them?
10.6 Hypothesis testing with infer
The “There is Only One Test” diagram mentioned in Section 10.2 was the inspiration for the infer pipeline that you saw for confidence intervals in Chapter 9. For hypothesis tests, we include one more verb into the pipeline: the hypothesize() verb. Its main argument is null which is either
"point"for point hypotheses involving a single sample or"independence"for testing for independence between two variables.
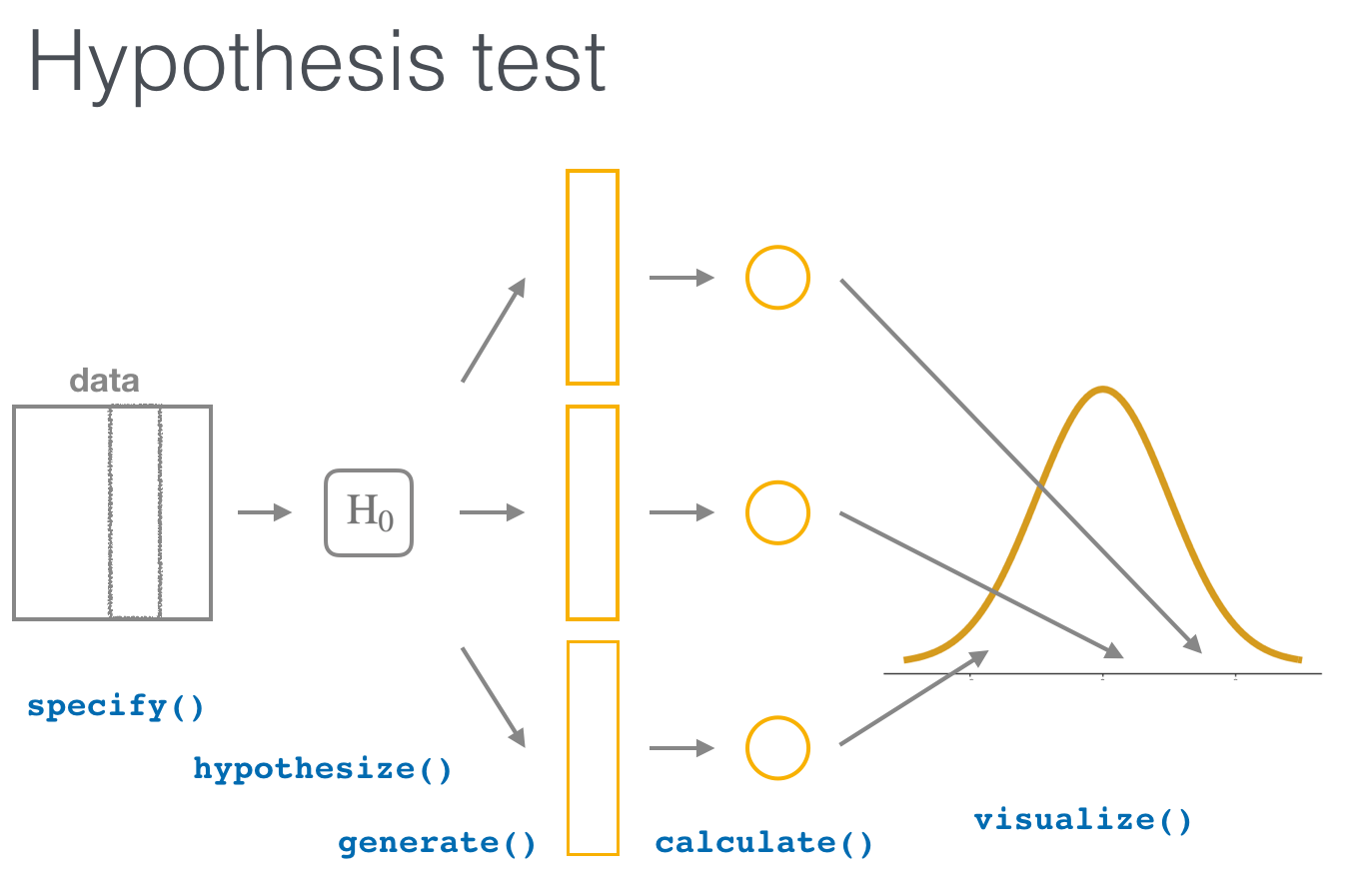
We’ll first explore the two variable case by comparing two means. Note the section headings here that refer to the “There is Only One Test” diagram. We will lay out the specifics for each problem using this framework and the infer pipeline together.
10.7 Example: Comparing two means
10.7.1 Randomization/permutation
We will now focus on building hypotheses looking at the difference between two population means in an example. We will denote population means using the Greek symbol \(\mu\) (pronounced “mu”). Thus, we will be looking to see if one group “out-performs” another group. This is quite possibly the most common type of statistical inference and serves as a basis for many other types of analyses when comparing the relationship between two variables.
Our null hypothesis will be of the form \(H_0: \mu_1 = \mu_2\), which can also be written as \(H_0: \mu_1 - \mu_2 = 0\). Our alternative hypothesis will be of the form \(H_0: \mu_1 \star \mu_2\) (or \(H_a: \mu_1 - \mu_2 \, \star \, 0\)) where \(\star\) = \(<\), \(\ne\), or \(>\) depending on the context of the problem. You needn’t focus on these new symbols too much at this point. It will just be a shortcut way for us to describe our hypotheses.
As we saw in Chapter 9, bootstrapping is a valuable tool when conducting inferences based on one or two population variables. We will see that the process of randomization (also known as permutation) will be valuable in conducting tests comparing quantitative values from two groups.
10.7.2 Comparing action and romance movies
The movies dataset in the ggplot2movies package contains information on a large number of movies that have been rated by users of IMDB.com (Wickham 2015). We are interested in the question here of whether Action movies are rated higher on IMDB than Romance movies. We will first need to do a little bit of data wrangling using the ideas from Chapter 4 to get the data in the form that we would like:
movies_trimmed <- movies %>%
select(title, year, rating, Action, Romance)Note that Action and Romance are binary variables here. To remove any overlap of movies (and potential confusion) that are both Action and Romance, we will remove them from our population:
movies_trimmed <- movies_trimmed %>%
filter(!(Action == 1 & Romance == 1))We will now create a new variable called genre that specifies whether a movie in our movies_trimmed data frame is an "Action" movie, a "Romance" movie, or "Neither". We aren’t really interested in the "Neither" category here so we will exclude those rows as well. Lastly, the Action and Romance columns are not needed anymore since they are encoded in the genre column.
movies_trimmed <- movies_trimmed %>%
mutate(genre = case_when(Action == 1 ~ "Action",
Romance == 1 ~ "Romance",
TRUE ~ "Neither")) %>%
filter(genre != "Neither") %>%
select(-Action, -Romance)The case_when function is useful for assigning values in a new variable based on the values of another variable. The last step of TRUE ~ "Neither" is used when a particular movie is not set to either Action or Romance.
We are left with 8878 movies in our population dataset that focuses on only "Action" and "Romance" movies.
Learning check
(LC10.6) Why are the different genre variables stored as binary variables (1s and 0s) instead of just listing the genre as a column of values like “Action”, “Comedy”, etc.?
(LC10.7) What complications could come above with us excluding action romance movies? Should we question the results of our hypothesis test? Explain.
Let’s now visualize the distributions of rating across both levels of genre. Think about what type(s) of plot is/are appropriate here before you proceed:
ggplot(data = movies_trimmed, aes(x = genre, y = rating)) +
geom_boxplot()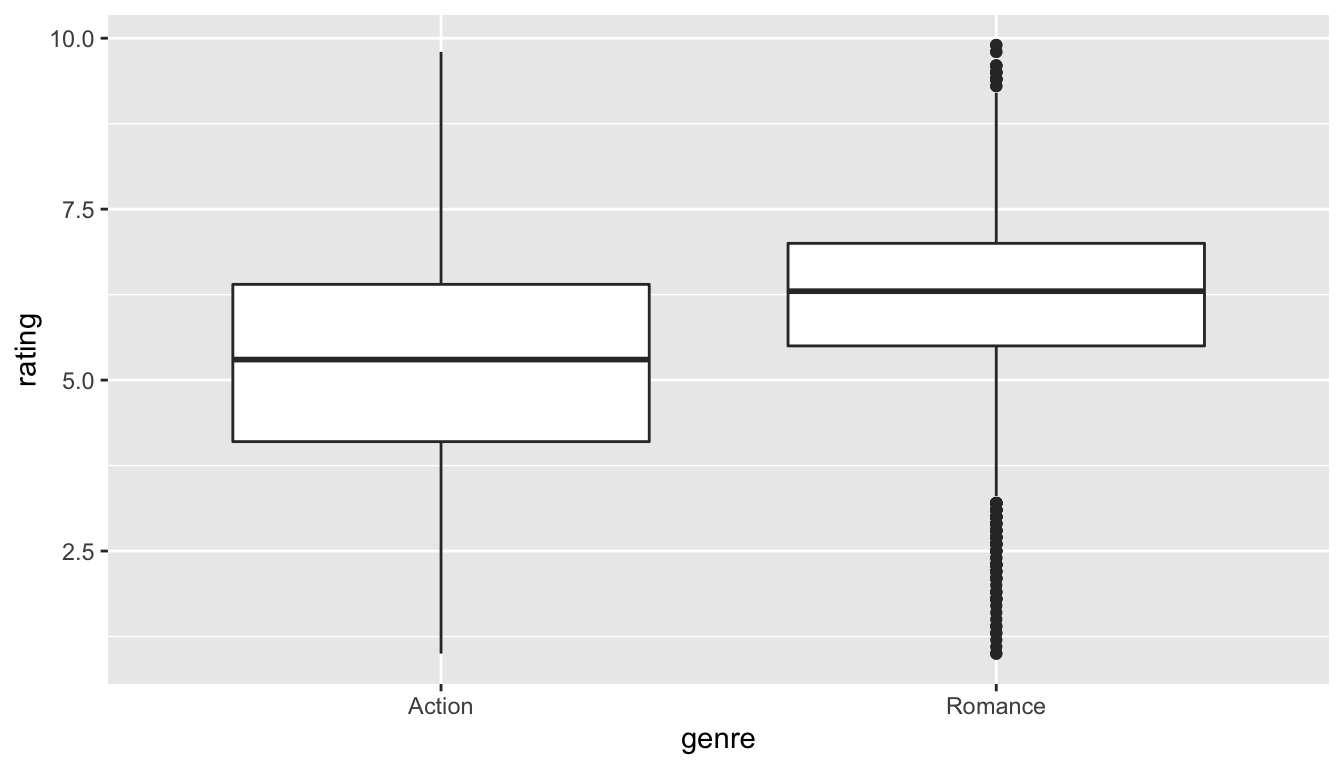
FIGURE 10.3: Rating vs genre in the population
We can see that the middle 50% of ratings for "Action" movies is more spread out than that of "Romance" movies in the population. "Romance" has outliers at both the top and bottoms of the scale though. We are initially interested in comparing the mean rating across these two groups so a faceted histogram may also be useful:
ggplot(data = movies_trimmed, mapping = aes(x = rating)) +
geom_histogram(binwidth = 1, color = "white") +
facet_grid(genre ~ .)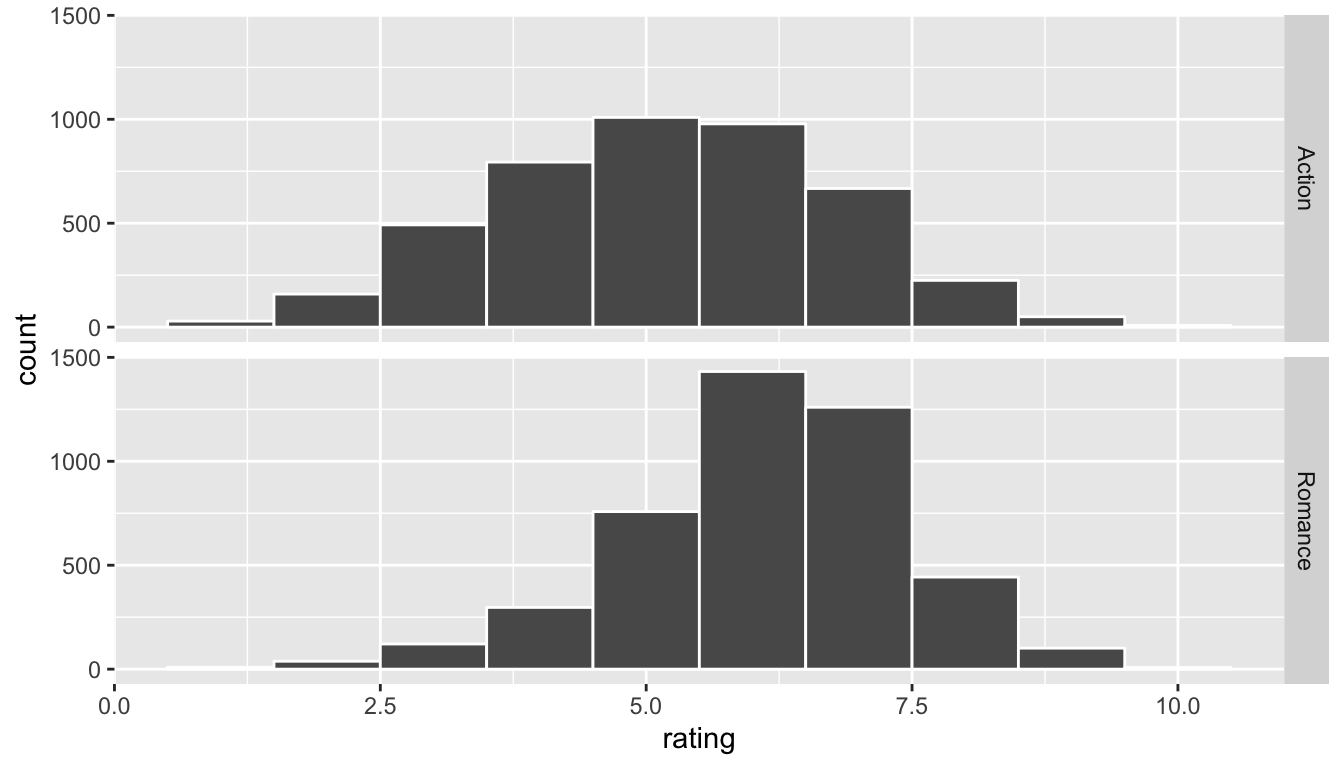
FIGURE 10.4: Faceted histogram of genre vs rating
Important note: Remember that we hardly ever have access to the population values as we do here. This example and the nycflights13 dataset were used to create a common flow from chapter to chapter. In nearly all circumstances, we’ll be needing to use only a sample of the population to try to infer conclusions about the unknown population parameter values. These examples do show a nice relationship between statistics (where data is usually small and more focused on experimental settings) and data science (where data is frequently large and collected without experimental conditions).
10.7.3 Sampling \(\rightarrow\) randomization
We can use hypothesis testing to investigate ways to determine, for example, whether a treatment has an effect over a control and other ways to statistically analyze if one group performs better than, worse than, or different than another. We are interested here in seeing how we can use a random sample of action movies and a random sample of romance movies from movies to determine if a statistical difference exists in the mean ratings of each group.
Learning check
(LC10.8) Define the relevant parameters here in terms of the populations of movies.
10.7.4 Data
Let’s select a random sample of 34 action movies and a random sample of 34 romance movies. (The number 34 was chosen somewhat arbitrarily here.)
set.seed(2017)
movies_genre_sample <- movies_trimmed %>%
group_by(genre) %>%
sample_n(34) %>%
ungroup()Note the addition of the ungroup() function here. This will be useful shortly in allowing us to permute the values of rating across genre. Our analysis does not work without this ungroup() function since the data stays grouped by the levels of genre without it.
We can now observe the distributions of our two sample ratings for both groups. Remember that these plots
should be rough approximations of our population distributions of movie ratings for "Action" and "Romance"
in our population of all movies in the movies data frame.
ggplot(data = movies_genre_sample, aes(x = genre, y = rating)) +
geom_boxplot()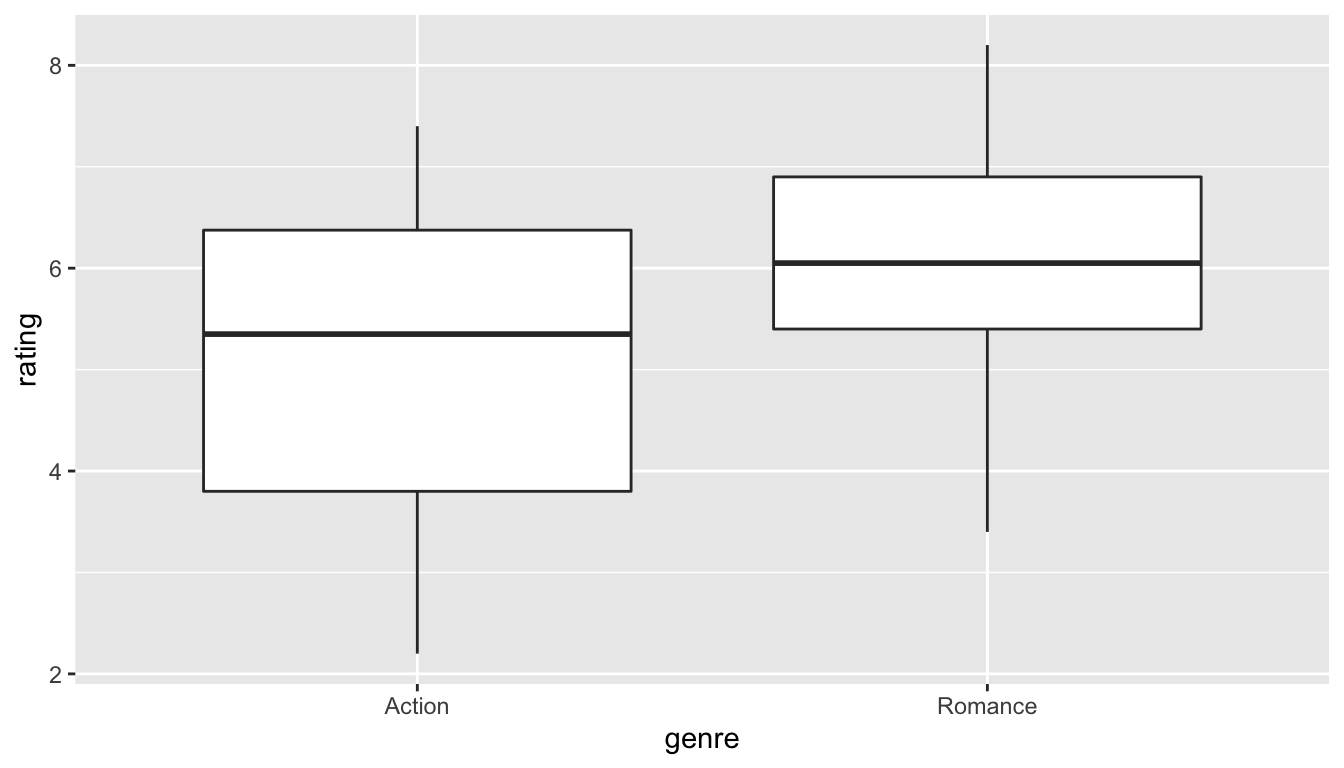
FIGURE 10.5: Genre vs rating for our sample
ggplot(data = movies_genre_sample, mapping = aes(x = rating)) +
geom_histogram(binwidth = 1, color = "white") +
facet_grid(genre ~ .)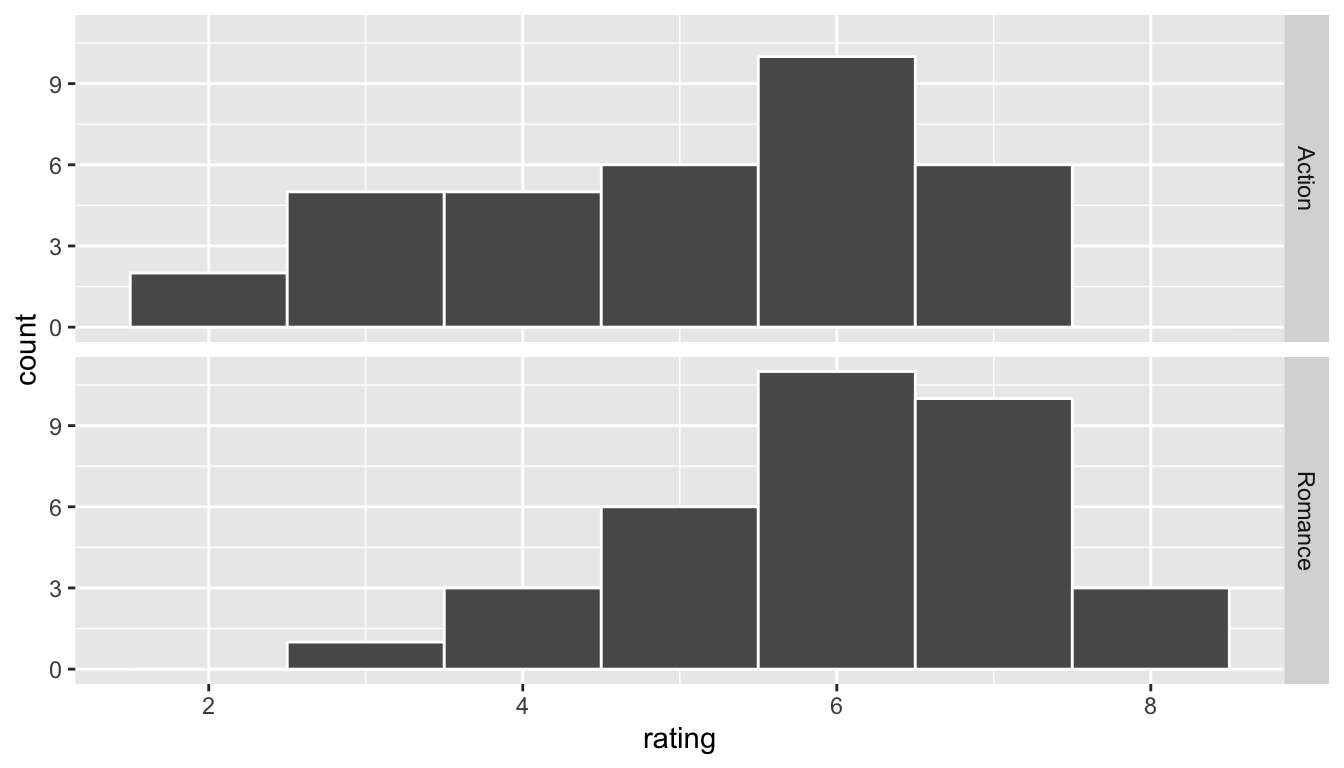
FIGURE 10.6: Genre vs rating for our sample as faceted histogram
Learning check
(LC10.9) What single value could we change to improve the approximation using the sample distribution on the population distribution?
Do we have reason to believe, based on the sample distributions of rating over the two groups of genre, that there is a significant difference between the mean rating for action movies compared to romance movies? It’s hard to say just based on the plots. The boxplot does show that the median sample rating is higher for romance movies, but the histogram isn’t as clear. The two groups have somewhat differently shaped distributions but they are both over similar values of rating. It’s often useful to calculate the mean and standard deviation as well, conditioned on the two levels.
summary_ratings <- movies_genre_sample %>%
group_by(genre) %>%
summarize(mean = mean(rating),
std_dev = sd(rating),
n = n())
summary_ratings# A tibble: 2 x 4
genre mean std_dev n
<chr> <dbl> <dbl> <int>
1 Action 5.11 1.49 34
2 Romance 6.06 1.15 34Learning check
(LC10.10) Why did we not specify na.rm = TRUE here as we did in Chapter 4?
We see that the sample mean rating for romance movies, \(\bar{x}_{r}\), is greater than the similar measure for action movies, \(\bar{x}_a\). But is it statistically significantly greater (thus, leading us to conclude that the means are statistically different)? The standard deviation can provide some insight here but with these standard deviations being so similar it’s still hard to say for sure.
Learning check
(LC10.11) Why might the standard deviation provide some insight about the means being statistically different or not?
10.7.5 Model of \(H_0\)
The hypotheses we specified can also be written in another form to better give us an idea of what we will be simulating to create our null distribution.
- \(H_0: \mu_r - \mu_a = 0\)
- \(H_a: \mu_r - \mu_a \ne 0\)
10.7.6 Test statistic \(\delta\)
We are, therefore, interested in seeing whether the difference in the sample means, \(\bar{x}_r - \bar{x}_a\), is statistically different than 0. We can now come back to our infer pipeline for computing our observed statistic. Note the order argument that shows the mean value for "Action" being subtracted from the mean value of "Romance".
10.7.7 Observed effect \(\delta^*\)
obs_diff <- movies_genre_sample %>%
specify(formula = rating ~ genre) %>%
calculate(stat = "diff in means", order = c("Romance", "Action"))
obs_diff# A tibble: 1 x 1
stat
<dbl>
1 0.95Our goal next is to figure out a random process with which to simulate the null hypothesis being true. Recall that \(H_0: \mu_r - \mu_a = 0\) corresponds to us assuming that the population means are the same. We would like to assume this is true and perform a random process to generate() data in the model of the null hypothesis.
10.7.8 Simulated data
Tactile simulation
Here, with us assuming the two population means are equal (\(H_0: \mu_r - \mu_a = 0\)), we can look at this from a tactile point of view by using index cards. There are \(n_r = 34\) data elements corresponding to romance movies and \(n_a = 34\) for action movies. We can write the 34 ratings from our sample for romance movies on one set of 34 index cards and the 34 ratings for action movies on another set of 34 index cards. (Note that the sample sizes need not be the same.)
The next step is to put the two stacks of index cards together, creating a new set of 68 cards. If we assume that the two population means are equal, we are saying that there is no association between ratings and genre (romance vs action). We can use the index cards to create two new stacks for romance and action movies. Note that the new “romance movie stack” will likely have some of the original action movies in it and likewise for the “action movie stack” including some romance movies from our original set. Since we are assuming that each card is equally likely to have appeared in either one of the stacks this makes sense. First, we must shuffle all the cards thoroughly. After doing so, in this case with equal values of sample sizes, we split the deck in half.
We then calculate the new sample mean rating of the romance deck, and also the new sample mean rating of the action deck. This creates one simulation of the samples that were collected originally. We next want to calculate a statistic from these two samples. Instead of actually doing the calculation using index cards, we can use R as we have before to simulate this process. Let’s do this just once and compare the results to what we see in movies_genre_sample.
movies_genre_sample %>%
specify(formula = rating ~ genre) %>%
hypothesize(null = "independence") %>%
generate(reps = 1) %>%
calculate(stat = "diff in means", order = c("Romance", "Action"))# A tibble: 1 x 1
stat
<dbl>
1 0.515Learning check
(LC10.12) How would the tactile shuffling of index cards change if we had different samples of say 20 action movies and 60 romance movies? Describe each step that would change.
(LC10.13) Why are we taking the difference in the means of the cards in the new shuffled decks?
10.7.9 Distribution of \(\delta\) under \(H_0\)
The generate() step completes a permutation sending values of ratings to potentially different values of genre from which they originally came. It simulates a shuffling of the ratings between the two levels of genre just as we could have done with index cards. We can now proceed in a similar way to what we have done previously with bootstrapping by repeating this process many times to create simulated samples, assuming the null hypothesis is true.
generated_samples <- movies_genre_sample %>%
specify(formula = rating ~ genre) %>%
hypothesize(null = "independence") %>%
generate(reps = 5000)A null distribution of simulated differences in sample means is created with the specification of stat = "diff in means" for the calculate() step. The null distribution is similar to the bootstrap distribution we saw in Chapter 9, but remember that it consists of statistics generated assuming the null hypothesis is true.
We can now plot the distribution of these simulated differences in means:
null_distribution_two_means %>% visualize()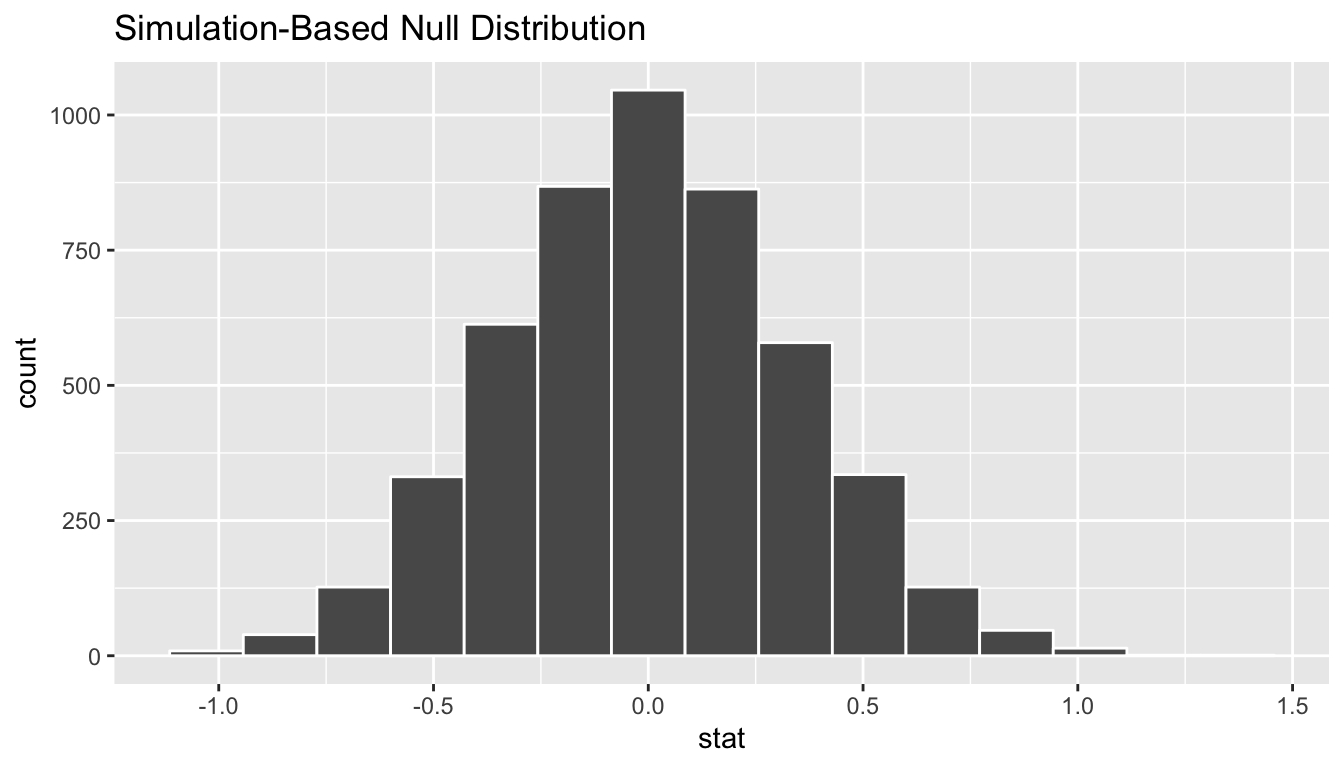
FIGURE 10.7: Simulated differences in means histogram
10.7.10 The p-value
Remember that we are interested in seeing where our observed sample mean difference of 0.95 falls on this null/randomization distribution. We are interested in simply a difference here so “more extreme” corresponds to values in both tails on the distribution. Let’s shade our null distribution to show a visual representation of our \(p\)-value:
null_distribution_two_means %>%
visualize(obs_stat = obs_diff, direction = "both")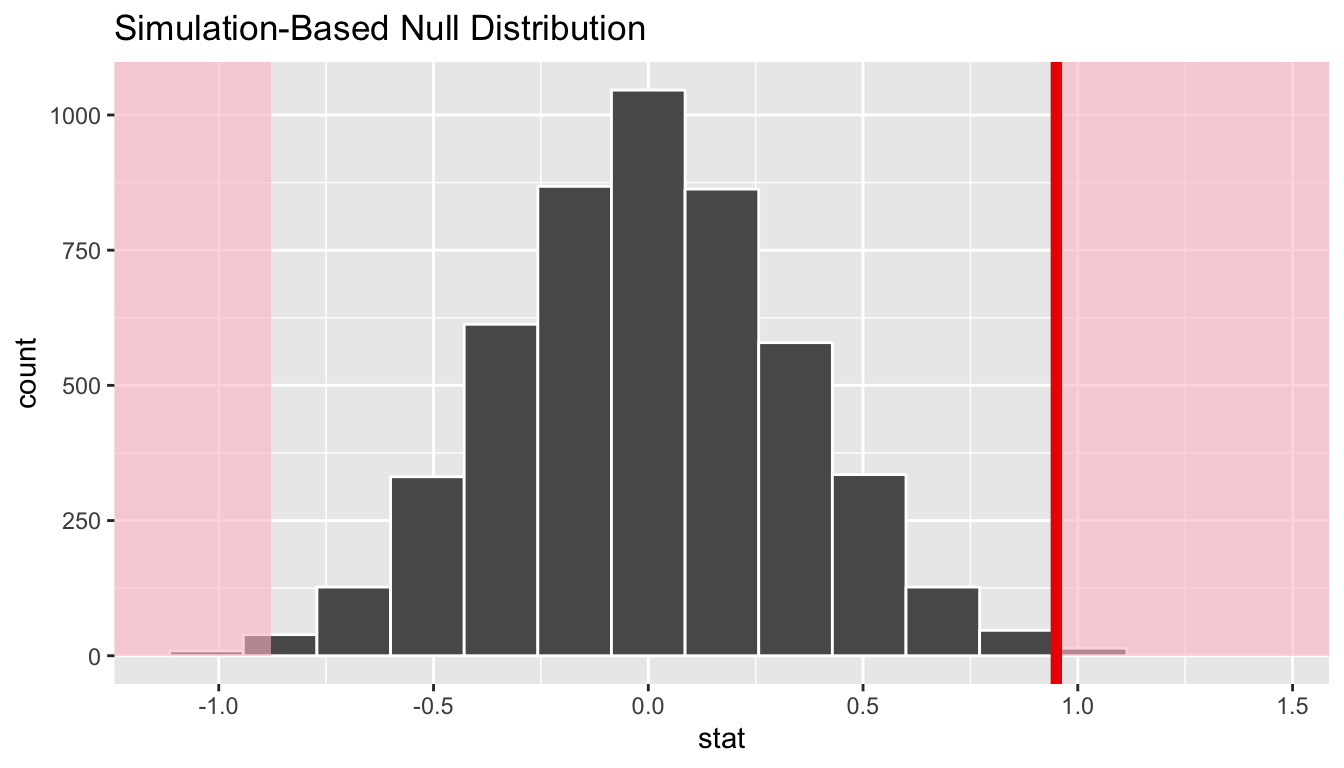
FIGURE 10.8: Shaded histogram to show p-value
Remember that the observed difference in means was 0.95. We have shaded red all values at or above that value and also shaded red those values at or below its negative value (since this is a two-tailed test). By giving obs_stat = obs_diff a vertical darker line is also shown at 0.95. To better estimate how large the \(p\)-value will be, we also increase the number of bins to 100 here from 20:
null_distribution_two_means %>%
visualize(bins = 100, obs_stat = obs_diff, direction = "both")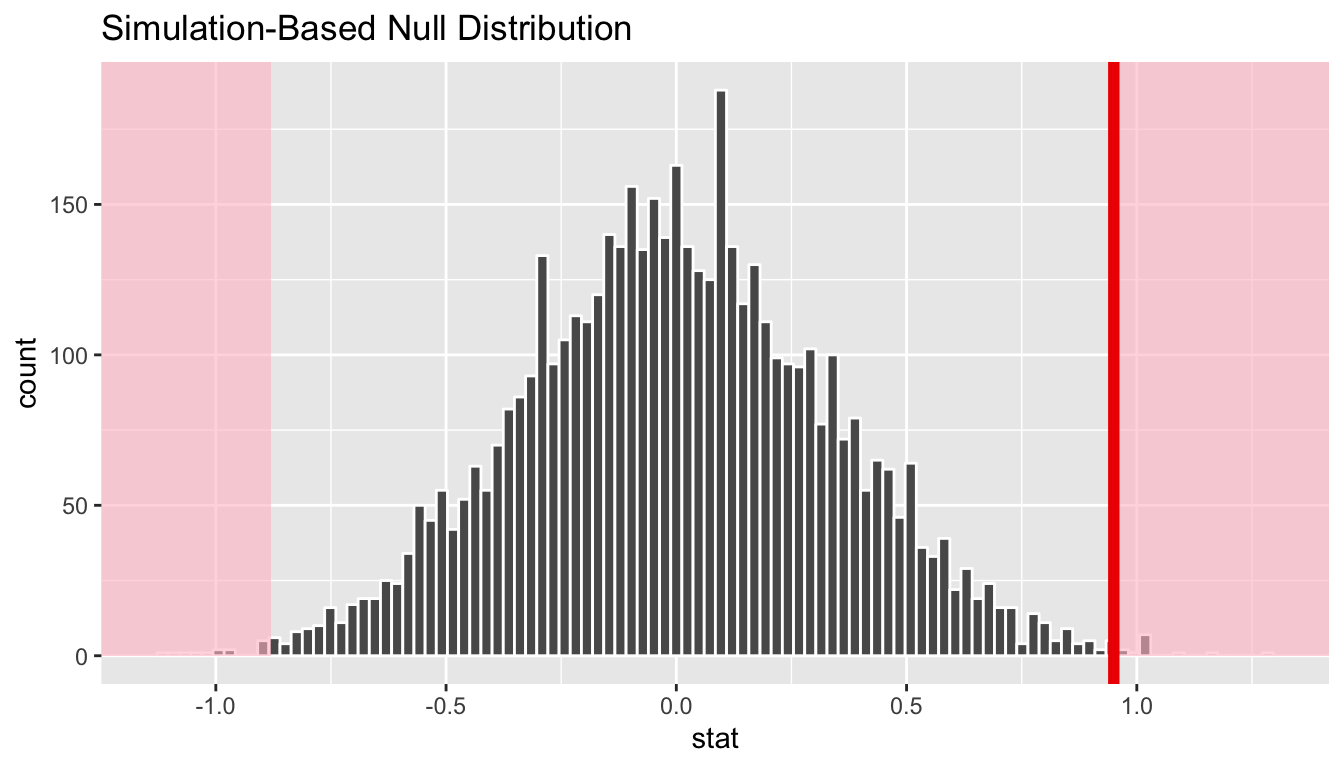
FIGURE 10.9: Histogram with vertical lines corresponding to observed statistic
At this point, it is important to take a guess as to what the \(p\)-value may be. We can see that there are only a few permuted differences as extreme or more extreme than our observed effect (in both directions). Maybe we guess that this \(p\)-value is somewhere around 2%, or maybe 3%, but certainly not 30% or more. Lastly, we calculate the \(p\)-value directly using infer:
pvalue <- null_distribution_two_means %>%
get_pvalue(obs_stat = obs_diff, direction = "both")
pvalue# A tibble: 1 x 1
p_value
<dbl>
1 0.006We have around 0.6% of values as extreme or more extreme than our observed statistic in both directions. Assuming we are using a 5% significance level for \(\alpha\), we have evidence supporting the conclusion that the mean rating for romance movies is different from that of action movies. The next important idea is to better understand just how much higher of a mean rating can we expect the romance movies to have compared to that of action movies.
10.7.11 Corresponding confidence interval
One of the great things about the infer pipeline is that going between hypothesis tests and confidence intervals is incredibly simple. To create a null distribution, we ran
null_distribution_two_means <- movies_genre_sample %>%
specify(formula = rating ~ genre) %>%
hypothesize(null = "independence") %>%
generate(reps = 5000) %>%
calculate(stat = "diff in means", order = c("Romance", "Action"))To get the corresponding bootstrap distribution with which we can compute a confidence interval, we can just remove or comment out the hypothesize() step since we are no longer assuming the null hypothesis is true when we bootstrap:
percentile_ci_two_means <- movies_genre_sample %>%
specify(formula = rating ~ genre) %>%
# hypothesize(null = "independence") %>%
generate(reps = 5000) %>%
calculate(stat = "diff in means", order = c("Romance", "Action")) %>%
get_ci()Setting `type = "bootstrap"` in `generate()`.percentile_ci_two_means# A tibble: 1 x 2
`2.5%` `97.5%`
<dbl> <dbl>
1 0.333 1.59Thus, we can expect the true mean of Romance movies on IMDB to have a rating 0.333 to 1.593 points higher than that of Action movies. Remember that this is based on bootstrapping using movies_genre_sample as our original sample and the confidence interval process being 95% reliable.
Learning check
(LC10.14) Conduct the same analysis comparing action movies versus romantic movies using the median rating instead of the mean rating? What was different and what was the same?
(LC10.15) What conclusions can you make from viewing the faceted histogram looking at rating versus genre that you couldn’t see when looking at the boxplot?
(LC10.16) Describe in a paragraph how we used Allen Downey’s diagram to conclude if a statistical difference existed between mean movie ratings for action and romance movies.
(LC10.17) Why are we relatively confident that the distributions of the sample ratings will be good approximations of the population distributions of ratings for the two genres?
(LC10.18) Using the definition of “\(p\)-value”, write in words what the \(p\)-value represents for the hypothesis test above comparing the mean rating of romance to action movies.
(LC10.19) What is the value of the \(p\)-value for the hypothesis test comparing the mean rating of romance to action movies?
(LC10.20) Do the results of the hypothesis test match up with the original plots we made looking at the population of movies? Why or why not?
10.7.12 Summary
To review, these are the steps one would take whenever you’d like to do a hypothesis test comparing values from the distributions of two groups:
Simulate many samples using a random process that matches the way the original data were collected and that assumes the null hypothesis is true.
Collect the values of a sample statistic for each sample created using this random process to build a null distribution.
Assess the significance of the original sample by determining where its sample statistic lies in the null distribution.
If the proportion of values as extreme or more extreme than the observed statistic in the randomization distribution is smaller than the pre-determined significance level \(\alpha\), we reject \(H_0\). Otherwise, we fail to reject \(H_0\). (If no significance level is given, one can assume \(\alpha = 0.05\).)
10.8 Building theory-based methods using computation
As a point of reference, we will now discuss the traditional theory-based way to conduct the hypothesis test for determining if there is a statistically significant difference in the sample mean rating of Action movies versus Romance movies. This method and ones like it work very well when the assumptions are met in order to run the test. They are based on probability models and distributions such as the normal and \(t\)-distributions.
These traditional methods have been used for many decades back to the time when researchers didn’t have access to computers that could run 5000 simulations in a few seconds. They had to base their methods on probability theory instead. Many fields and researchers continue to use these methods and that is the biggest reason for their inclusion here. It’s important to remember that a \(t\)-test or a \(z\)-test is really just an approximation of what you have seen in this chapter already using simulation and randomization. The focus here is on understanding how the shape of the \(t\)-curve comes about without digging big into the mathematical underpinnings.
10.8.1 Example: \(t\)-test for two independent samples
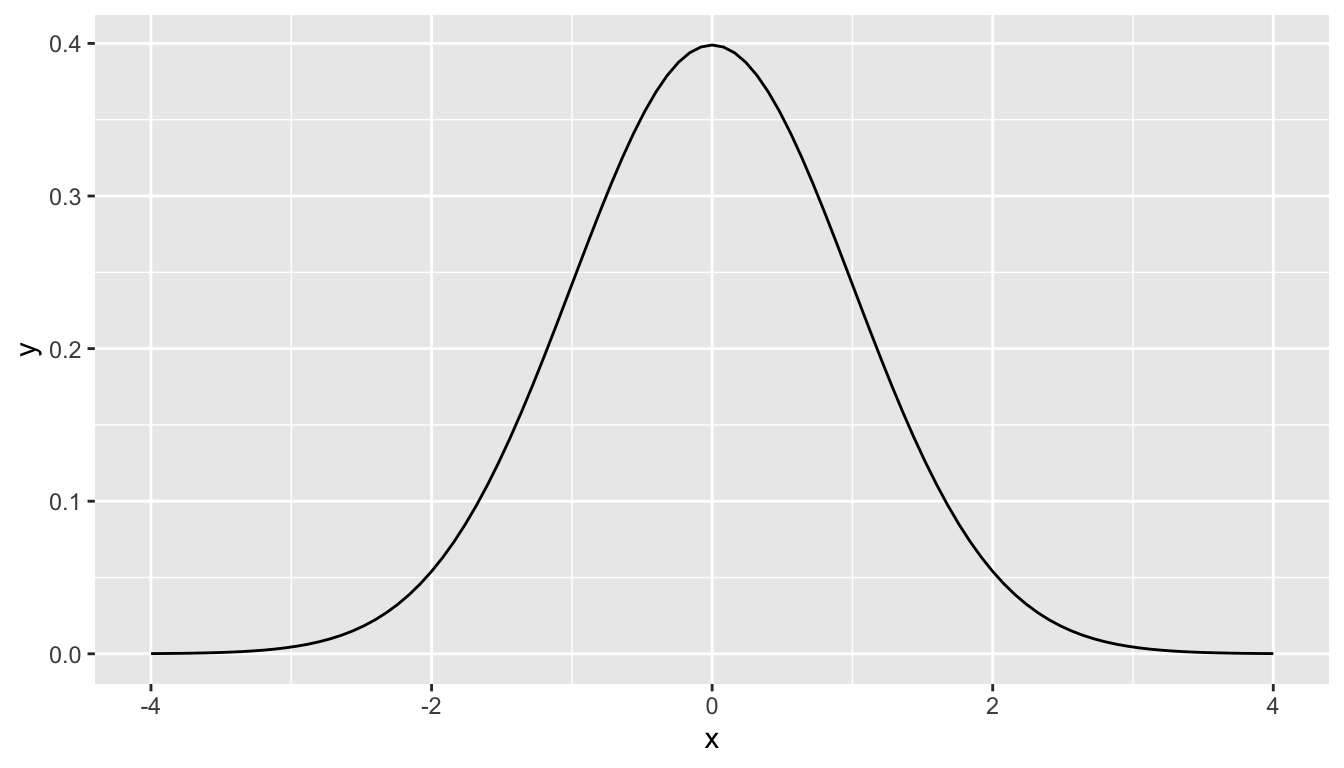
What is commonly done in statistics is the process of standardization. What this entails is calculating the mean and standard deviation of a variable. Then you subtract the mean from each value of your variable and divide by the standard deviation. The most common standardization is known as the \(z\)-score. The formula for a \(z\)-score is \[Z = \frac{x - \mu}{\sigma},\] where \(x\) represent the value of a variable, \(\mu\) represents the mean of the variable, and \(\sigma\) represents the standard deviation of the variable. Thus, if your variable has 10 elements, each one has a corresponding \(z\)-score that gives how many standard deviations away that value is from its mean. \(z\)-scores are normally distributed with mean 0 and standard deviation 1. They have the common, bell-shaped pattern seen below.
Recall, that we hardly ever know the mean and standard deviation of the population of interest. This is almost always the case when considering the means of two independent groups. To help account for us not knowing the population parameter values, we can use the sample statistics instead, but this comes with a bit of a price in terms of complexity.
Another form of standardization occurs when we need to use the sample standard deviations as estimates for the unknown population standard deviations. This standardization is often called the \(t\)-score. For the two independent samples case like what we have for comparing action movies to romance movies, the formula is \[T =\dfrac{ (\bar{x}_1 - \bar{x}_2) - (\mu_1 - \mu_2)}{ \sqrt{\dfrac{{s_1}^2}{n_1} + \dfrac{{s_2}^2}{n_2}} }\]
There is a lot to try to unpack here.
- \(\bar{x}_1\) is the sample mean response of the first group
- \(\bar{x}_2\) is the sample mean response of the second group
- \(\mu_1\) is the population mean response of the first group
- \(\mu_2\) is the population mean response of the second group
- \(s_1\) is the sample standard deviation of the response of the first group
- \(s_2\) is the sample standard deviation of the response of the second group
- \(n_1\) is the sample size of the first group
- \(n_2\) is the sample size of the second group
Assuming that the null hypothesis is true (\(H_0: \mu_1 - \mu_2 = 0\)), \(T\) is said to be distributed following a \(t\) distribution with degrees of freedom equal to the smaller value of \(n_1 - 1\) and \(n_2 - 1\). The “degrees of freedom” can be thought of measuring how different the \(t\) distribution will be as compared to a normal distribution. Small sample sizes lead to small degrees of freedom and, thus, \(t\) distributions that have more values in the tails of their distributions. Large sample sizes lead to large degrees of freedom and, thus, \(t\) distributions that closely align with the standard normal, bell-shaped curve.
So, assuming \(H_0\) is true, our formula simplifies a bit:
\[T =\dfrac{ \bar{x}_1 - \bar{x}_2}{ \sqrt{\dfrac{{s_1}^2}{n_1} + \dfrac{{s_2}^2}{n_2}} }.\]
We have already built an approximation for what we think the distribution of \(\delta = \bar{x}_1 - \bar{x}_2\) looks like using randomization above. Recall this distribution:
ggplot(data = null_distribution_two_means, aes(x = stat)) +
geom_histogram(color = "white", bins = 20)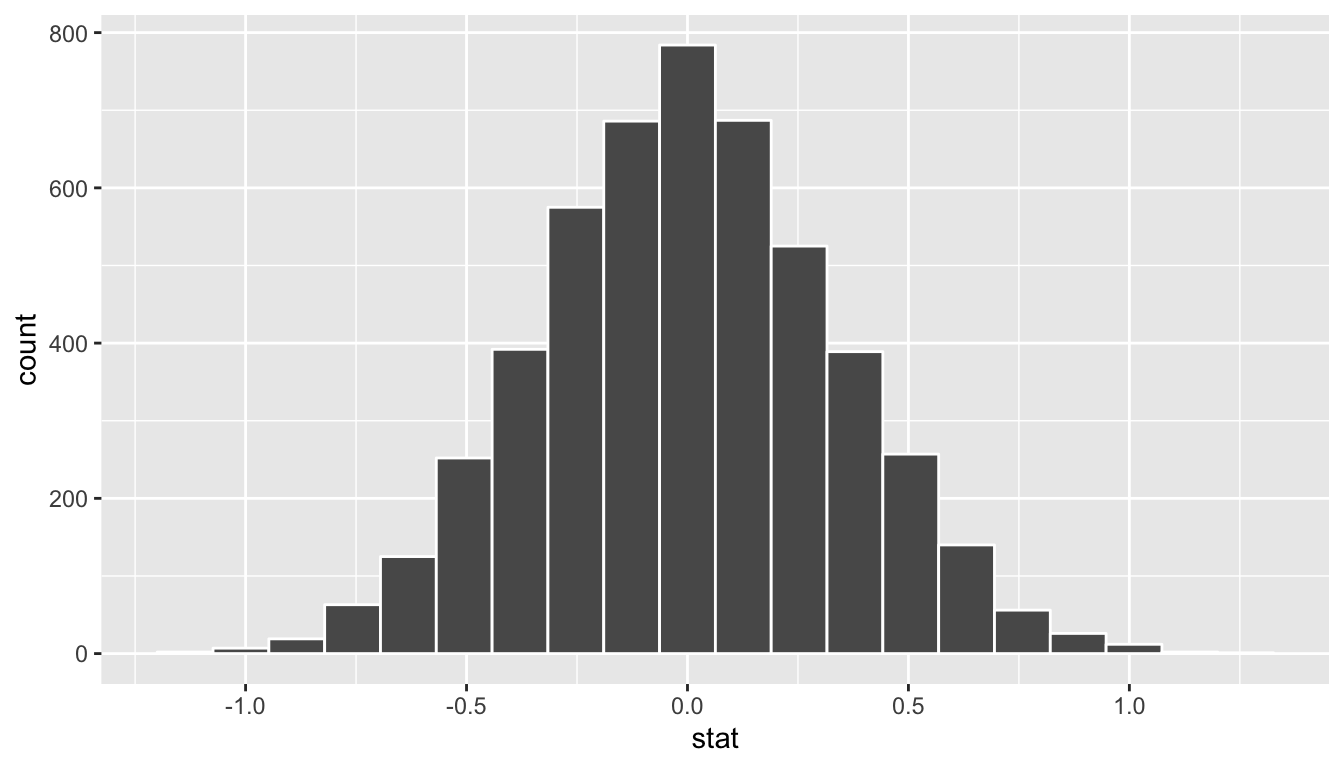
FIGURE 10.10: Simulated differences in means histogram
The infer package also includes some built-in theory-based statistics as well, so instead of going through the process of trying to transform the difference into a standardized form, we can just provide a different value for stat in calculate(). Recall the generated_samples data frame created via:
generated_samples <- movies_genre_sample %>%
specify(formula = rating ~ genre) %>%
hypothesize(null = "independence") %>%
generate(reps = 5000)We can now created a null distribution of \(t\) statistics:
null_distribution_t <- generated_samples %>%
calculate(stat = "t", order = c("Romance", "Action"))
null_distribution_t %>% visualize()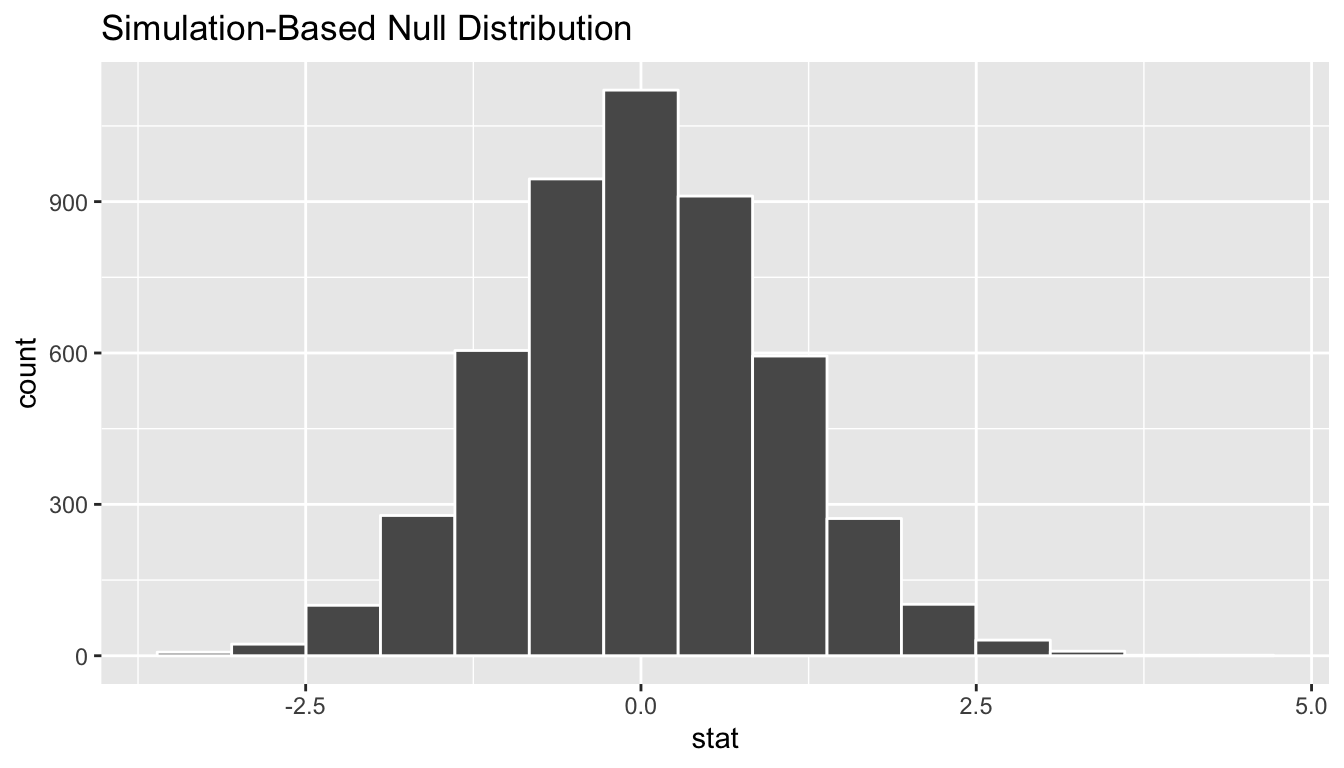
We see that the shape of this stat = "t" distribution is the same as that of stat = "diff in means". The scale has changed though with the \(t\) values having less spread than the difference in means.
A traditional \(t\)-test doesn’t look at this simulated distribution, but instead it looks at the \(t\)-curve with degrees of freedom equal to 62.029. We can overlay this distribution over the top of our permuted \(t\) statistics using the method = "both" setting in visualize().
null_distribution_t %>%
visualize(method = "both")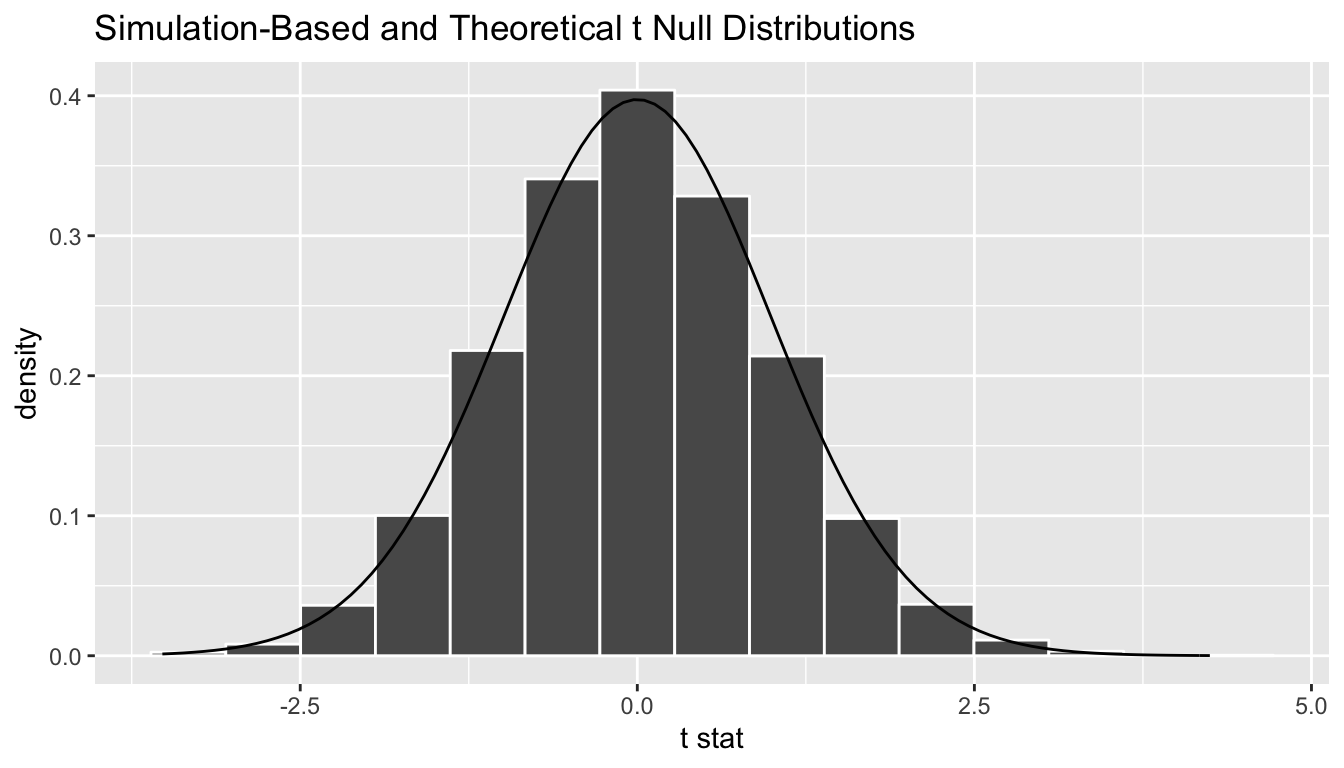
We can see that the curve does a good job of approximating the randomization distribution here. (More on when to expect for this to be the case when we discuss conditions for the \(t\)-test in a bit.) To calculate the \(p\)-value in this case, we need to figure out how much of the total area under the \(t\)-curve is at our observed \(T\)-statistic or more, plus also adding the area under the curve at the negative value of the observed \(T\)-statistic or below. (Remember this is a two-tailed test so we are looking for a difference–values in the tails of either direction.) Just as we converted all of the simulated values to \(T\)-statistics, we must also do so for our observed effect \(\delta^*\):
obs_t <- movies_genre_sample %>%
specify(formula = rating ~ genre) %>%
calculate(stat = "t", order = c("Romance", "Action"))So graphically we are interested in finding the percentage of values that are at or above 2.945 or at or below -2.945.
null_distribution_t %>%
visualize(method = "both", obs_stat = obs_t, direction = "both")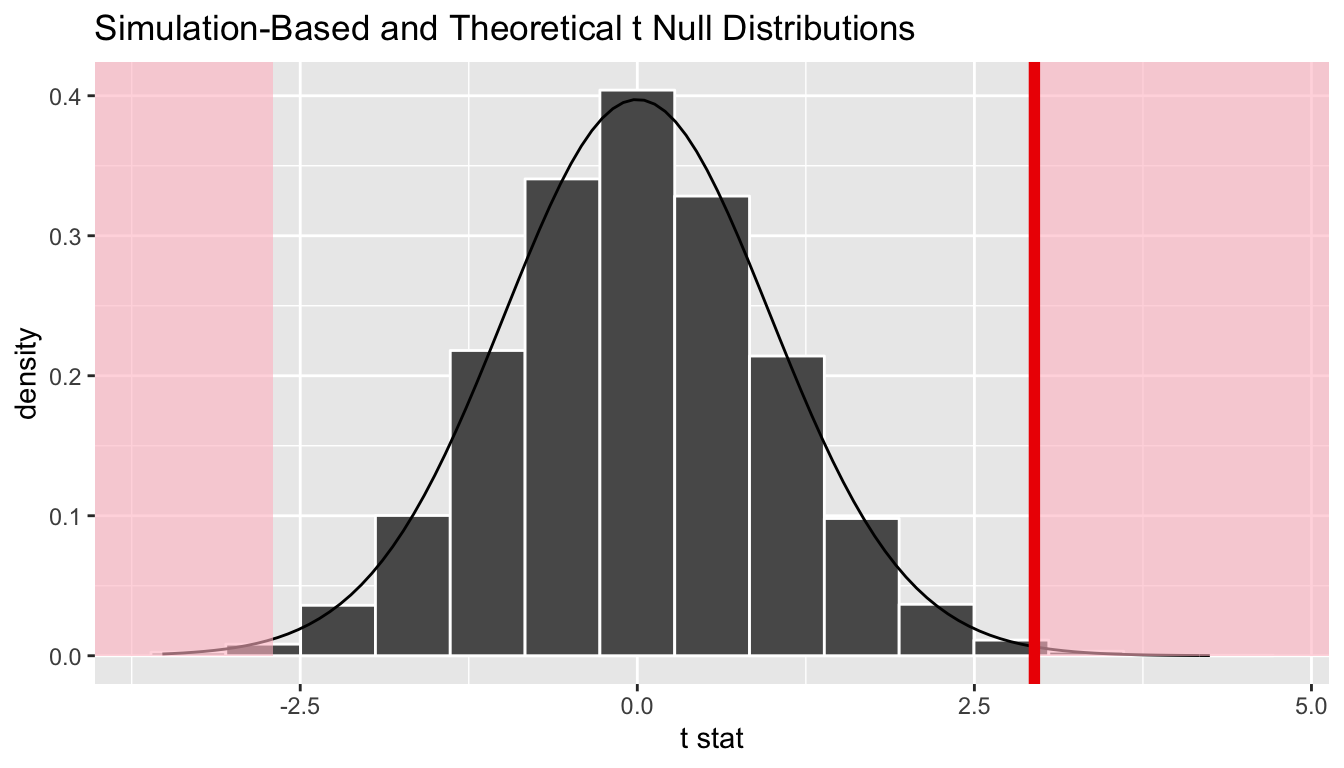
As we might have expected with this just being a standardization of the difference in means statistic that produced a small \(p\)-value, we also have a very small one here.
10.8.2 Conditions for t-test
The infer package does not automatically check conditions for the theoretical methods to work and this warning was given when we used method = "both". In order for the results of the \(t\)-test to be valid, three conditions must be met:
- Independent observations in both samples
- Nearly normal populations OR large sample sizes (\(n \ge 30\))
- Independently selected samples
Condition 1: This is met since we sampled at random using R from our population.
Condition 2: Recall from Figure 10.4, that we know how the populations are distributed. Both of them are close to normally distributed. If we are a little concerned about this assumption, we also do have samples of size larger than 30 (\(n_1 = n_2 = 34\)).
Condition 3: This is met since there is no natural pairing of a movie in the Action group to a movie in the Romance group.
Since all three conditions are met, we can be reasonably certain that the theory-based test will match the results of the randomization-based test using shuffling. Remember that theory-based tests can produce some incorrect results in these assumptions are not carefully checked. The only assumption for randomization and computational-based methods is that the sample is selected at random. They are our preference and we strongly believe they should be yours as well, but it’s important to also see how the theory-based tests can be done and used as an approximation for the computational techniques until at least more researchers are using these techniques that utilize the power of computers.
10.9 Conclusion
We conclude by showing the infer pipeline diagram. In Chapter 11, we’ll come back to regression and see how the ideas covered in Chapter 9 and this chapter can help in understanding the significance of predictors in modeling.

10.9.1 Script of R code
An R script file of all R code used in this chapter is available here.
References
Wickham, Hadley. 2015. Ggplot2movies: Movies Data. https://CRAN.R-project.org/package=ggplot2movies.